Temperature dependent average observable#
This is a more difficult case because the derivatives are more complicated. However, this case has also been coded in the library. Extra data will need to be provided, but then everything is handled by flags in the code for creating the data and models. The catch is that we cannot foresee every way that an observable may depend on the extrapolation variable. But if the derivatives of the observable being averaged with respect to the extrapolation variable are known up to the desired order, we can incorporate these into our computation of extrapolation and interpolation coefficients. That means these must also be provided with the input data.
For our averaged quantity that depends explicitly on temperature, we select the average dimensionless potential energy of a single ideal gas particle, \(\beta u = \langle \beta a x \rangle = \langle \beta x \rangle\) where \(a=1\) for simplicity. The average is over all particles and configurations.
Everything can be set up in pretty much the same way as Case 1. EXCEPT that we now have to provide not only data for the observable, but also its derivatives in \(\beta\). The derivatives must be supplied up to the desired maximum order. This is a bit cumbersome in general, but hopefully your explicit dependence is polynomial (as it is here) or exponential in \(\beta\). In these cases, derivatives of arbitrarily high order are trivial to compute.
So now the observable data can have 3 dimensions - for each configurational snapshot, for each derivative order starting at zero (i.e., the observable value) and going to the maximum desired, and for each element in the observable array. Note that the second dimension represents the derivatives of the observable with respect to the extrapolation variable. So for the first derivative, this is just \(x\) in this example and for all subsequent derivatives up to the desired order, we pad with zeros.
%matplotlib inline
# random number generator
import cmomy
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import xarray as xr
# Import idealgas module
from thermoextrap import idealgas
rng = cmomy.random.default_rng(seed=0)
# Define test betas and reference beta
betas = np.arange(0.1, 10.0, 0.5)
beta_ref = betas[11]
vol = 1.0
# Define orders to extrapolate to
orders = [1, 2, 4, 6]
order = orders[-1]
npart = 1000 # Number of particles (in single configuration)
nconfig = 100_000 # Number of configurations
# Generate all the data we could want
xdata, udata = idealgas.generate_data((nconfig, npart), beta_ref, vol)
# You can use numpy and just wrap with xarray after...
xdataDepend = np.array([xdata * beta_ref, xdata])
xdataDepend = np.vstack((xdataDepend, np.zeros((orders[-1] - 1, xdata.shape[0]))))
xdata = xr.DataArray(xdata, dims=["rec"])
udata = xr.DataArray(udata, dims=["rec"])
# Note the naming of dimensions here and see "Data_Organization" for a full explanation
xdataDepend = xr.DataArray(
xdataDepend,
dims=["deriv", "rec"],
coords={"deriv": np.arange(xdataDepend.shape[0])},
)
print(xdataDepend)
# # Or you can accomplish this with xarray if you really want to...
# xdata = xr.DataArray(xdata, dims=['rec'])
# udata = xr.DataArray(udata, dims=['rec'])
# xdataDepend = (
# xr.concat([xdata*beta_ref, xdata], dim='deriv')
# .assign_coords(deriv=lambda x: np.arange(x.sizes['deriv']))
# .reindex(deriv=np.arange(orders[-1] + 1))
# .fillna(0.0)
# )
# print(xdataDepend)
<xarray.DataArray (deriv: 7, rec: 100000)> Size: 6MB
array([[1.0138, 0.9448, 0.9595, ..., 0.9873, 0.986 , 1.0242],
[0.181 , 0.1687, 0.1713, ..., 0.1763, 0.1761, 0.1829],
[0. , 0. , 0. , ..., 0. , 0. , 0. ],
...,
[0. , 0. , 0. , ..., 0. , 0. , 0. ],
[0. , 0. , 0. , ..., 0. , 0. , 0. ],
[0. , 0. , 0. , ..., 0. , 0. , 0. ]])
Coordinates:
* deriv (deriv) int64 56B 0 1 2 3 4 5 6
Dimensions without coordinates: rec
import thermoextrap as xtrap
# Create the model and data, here with the data object just created inside the call for the model
# The data is always accessible directly as model.data
order = orders[-1]
xem_dep = xtrap.beta.factory_extrapmodel(
beta=beta_ref,
data=xtrap.DataCentralMomentsVals.from_vals(
uv=udata,
xv=xdataDepend,
# by specifying deriv dimension, trigger doing coef calculation with explicit derivatives
deriv_dim="deriv",
order=orders[-1],
central=True,
),
)
# Check the derivatives
print("Model parameters (derivatives):")
print(xem_dep.derivs(norm=False))
print("\n")
# Finally, look at predictions
print("Model predictions:")
print(xem_dep.predict(betas[:4], order=2))
print("\n")
Model parameters (derivatives):
<xarray.DataArray (order: 7)> Size: 56B
array([ 0.9792, 0.0167, -0.0127, -0.0042, -0.6049, 1.8554, 2.1772])
Dimensions without coordinates: order
Model predictions:
<xarray.DataArray (beta: 4)> Size: 32B
array([0.6949, 0.7366, 0.7752, 0.8106])
Coordinates:
* beta (beta) float64 32B 0.1 0.6 1.1 1.6
dalpha (beta) float64 32B -5.5 -5.0 -4.5 -4.0
beta0 float64 8B 5.6
# And bootstrapped uncertainties
print("Bootstrapped uncertainties in predictions:")
print(
xem_dep
.resample(sampler={"nrep": 100}, parallel=True)
.predict(betas[:4], order=2)
.std("rep")
)
Bootstrapped uncertainties in predictions:
<xarray.DataArray (beta: 4)> Size: 32B
array([0.0997, 0.0824, 0.0667, 0.0527])
Coordinates:
* beta (beta) float64 32B 0.1 0.6 1.1 1.6
dalpha (beta) float64 32B -5.5 -5.0 -4.5 -4.0
beta0 float64 8B 5.6
fig, ax = plt.subplots(len(orders), sharex=True, sharey=True)
nsampvals = np.array((10.0 * np.ones(5)) ** np.arange(1, 6), dtype=int)
nsampcolors = plt.cm.viridis(np.arange(0.0, 1.0, float(1.0 / len(nsampvals))))
# First plot the analytical result
for a in ax:
a.plot(betas, betas * idealgas.x_ave(betas, vol), "k--", linewidth=2.0)
# Next look at extrapolation with an infinite number of samples
# This is possible in the ideal gas model in both temperature and volume
for j, o in enumerate(orders):
trueExtrap, trueDerivs = idealgas.x_beta_extrap_depend(o, beta_ref, betas, vol)
ax[j].plot(betas, trueExtrap, "r-", zorder=0)
if j == len(orders) - 1:
print(f"True extrapolation coefficients: {trueDerivs}")
for i, n in enumerate(nsampvals):
thisinds = rng.choice(len(xdata), size=n, replace=False)
# Get parameters for extrapolation model with this data by training it - the parameters are the derivatives
xem_dep = xtrap.beta.factory_extrapmodel(
beta=beta_ref,
xalpha=True,
data=xtrap.DataCentralMomentsVals.from_vals(
uv=udata[thisinds],
xv=xdataDepend.sel(rec=thisinds),
deriv_dim="deriv",
central=True,
order=order,
),
)
out = xem_dep.predict(betas, cumsum=True)
print(f"\t With N_configs = {n:6}: {xem_dep.derivs(norm=False).values.flatten()}")
for j, o in enumerate(orders):
out.sel(order=o).plot(
marker="s",
ms=4,
color=nsampcolors[i],
ls="None",
label=f"N={n}",
ax=ax[j],
)
ax[2].set_ylabel(r"$\langle \beta x \rangle$")
ax[-1].set_xlabel(r"$\beta$")
for j, o in enumerate(orders):
ax[j].annotate(f"O({o}) Extrapolation", xy=(0.4, 0.7), xycoords="axes fraction")
ax[-1].set_ylim((0.0, 2.0))
ax[-1].yaxis.set_major_locator(mpl.ticker.MaxNLocator(nbins=4, prune="both"))
fig.tight_layout()
fig.subplots_adjust(hspace=0.0)
for a in ax:
a.set_title(None)
plt.show()
True extrapolation coefficients: [ 9.7922e-01 1.7150e-02 -1.3566e-02 1.0069e-02 -6.7219e-03 3.6244e-03
-9.3213e-04]
With N_configs = 10: [ 9.7620e-01 6.3382e-02 -1.5816e-01 8.3563e-01 1.7880e+01 1.0777e+02
-3.1199e+03]
With N_configs = 100: [ 9.8067e-01 4.3129e-02 1.6502e-01 -1.1619e+00 1.0416e+01 6.0027e+01
-3.1348e+03]
With N_configs = 1000: [ 9.8033e-01 1.9356e-02 3.7339e-02 1.8383e-01 -8.0818e-01 -4.5850e+01
-6.0897e+01]
With N_configs = 10000: [ 9.7936e-01 1.7196e-02 2.1037e-02 2.1810e-01 -4.0756e+00 2.2653e+01
-2.0604e+01]
With N_configs = 100000: [ 0.9792 0.0167 -0.0127 -0.0042 -0.6049 1.8554 2.1772]
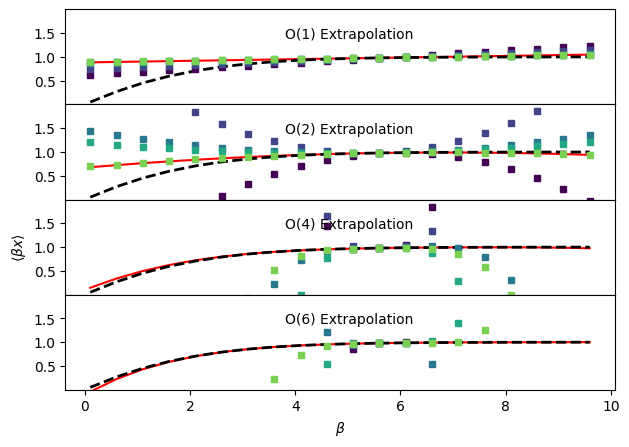
In each of the figures, the true behavior is shown as a black dashed line, the analytical result (infinite sampling) for each order of extrapolation is shown as a red solid line and the results with 10, 100, 1000, … 100000 randomly sampled configurations are shown with purple (fewer samples) to green (more samples) circles. For higher order extrapolation, the analytical, infinite sampling result matches very closely with the true temperature dependence of \(\langle x \rangle\). However, the finite-sampling results are in practice very poor due to difficulties in accurately estimating the higher-order moments of the potential energy distribution. The higher orders are actually quite accurate (if you try zooming in) close to the point we’re extrapolating from, but the error grows very quickly as we move further away.