|
HTGS
v2.0
The Hybrid Task Graph Scheduler
|
|
HTGS
v2.0
The Hybrid Task Graph Scheduler
|
Disclaimer: NIST-developed software is provided by NIST as a public service. You may use, copy and distribute copies of the software in any medium, provided that you keep intact this entire notice. You may improve, modify and create derivative works of the software or any portion of the software, and you may copy and distribute such modifications or works. Modified works should carry a notice stating that you changed the software and should note the date and nature of any such change. Please explicitly acknowledge the National Institute of Standards and Technology as the source of the software.
NIST-developed software is expressly provided “AS IS.” NIST MAKES NO WARRANTY OF ANY KIND, EXPRESS, IMPLIED, IN FACT OR ARISING BY OPERATION OF LAW, INCLUDING, WITHOUT LIMITATION, THE IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, NON-INFRINGEMENT AND DATA ACCURACY. NIST NEITHER REPRESENTS NOR WARRANTS THAT THE OPERATION OF THE SOFTWARE WILL BE UNINTERRUPTED OR ERROR-FREE, OR THAT ANY DEFECTS WILL BE CORRECTED. NIST DOES NOT WARRANT OR MAKE ANY REPRESENTATIONS REGARDING THE USE OF THE SOFTWARE OR THE RESULTS THEREOF, INCLUDING BUT NOT LIMITED TO THE CORRECTNESS, ACCURACY, RELIABILITY, OR USEFULNESS OF THE SOFTWARE.
You are solely responsible for determining the appropriateness of using and distributing the software and you assume all risks associated with its use, including but not limited to the risks and costs of program errors, compliance with applicable laws, damage to or loss of data, programs or equipment, and the unavailability or interruption of operation. This software is not intended to be used in any situation where a failure could cause risk of injury or damage to property. The software developed by NIST employees is not subject to copyright protection within the United States.
The intent of the Hybrid Task Graph Scheduler (HTGS) API is to transform an algorithm into a pipelined workflow system, which aims at fully utilizing a high performance compute system (multi-core CPUs, multiple accelerators, and high-speed I/O). HTGS defines an abstract execution model, framework, and API.
The HTGS model combines two paradigms, dataflow and task scheduling. Dataflow semantics represents an algorithm at a high-level of abstraction as a dataflow graph, similar to signal processing dataflow graphs. Task scheduling provides the threading model. A variant of task scheduling is used in which a task is assigned a pool of threads, which processes data using a shared queue. In this way data is sent to each task, which processes each item independently using the thread pool. This method of parallelism and orchestration requires a deep understanding of an algorithm and how to decompose the problem domain, which is required when parallelizing any algorithm.
The HTGS framework defines the components for building HTGS task graphs: tasks, bookkeepers, memory managers, and execution pipelines. These components are defined in such a way to provide a separation of concerns between computation, state maintenance, memory, and scalability. Through this representation an algorithm can be approached at a high level of abstraction.
The HTGS API is used to implement an algorithm that is represented within the HTGS framework. The API is designed in such a way that the graph representation from the model and framework is explicit. This allows for mapping the analysis phase of using HTGS with the implementation (and back). The primary use of this representation is to allow rapid prototyping and experimentation for performance.
The general idea with using HTGS is to overlap I/O with computation. I/O can be represented by disk, network, PCI express, or any metric that involves shipping data closer to the compute hardware. HTGS tasks should operate within memory for that compute hardware, such that the underlying task implementation be designed to improve utilization on the desired architecture (i.e. use vector processing units). Ultimately, HTGS provides abstractions for four components, which we treat as first-class issues: (1) Memory management, (2) Concurrency, (3) Expressing data locality, and (4) Managing data dependencies.
There are five steps in the HTGS design methodology, as shown below. The first three steps are white-board stages; the remaining steps are coding and revisiting of the pictoral stages.
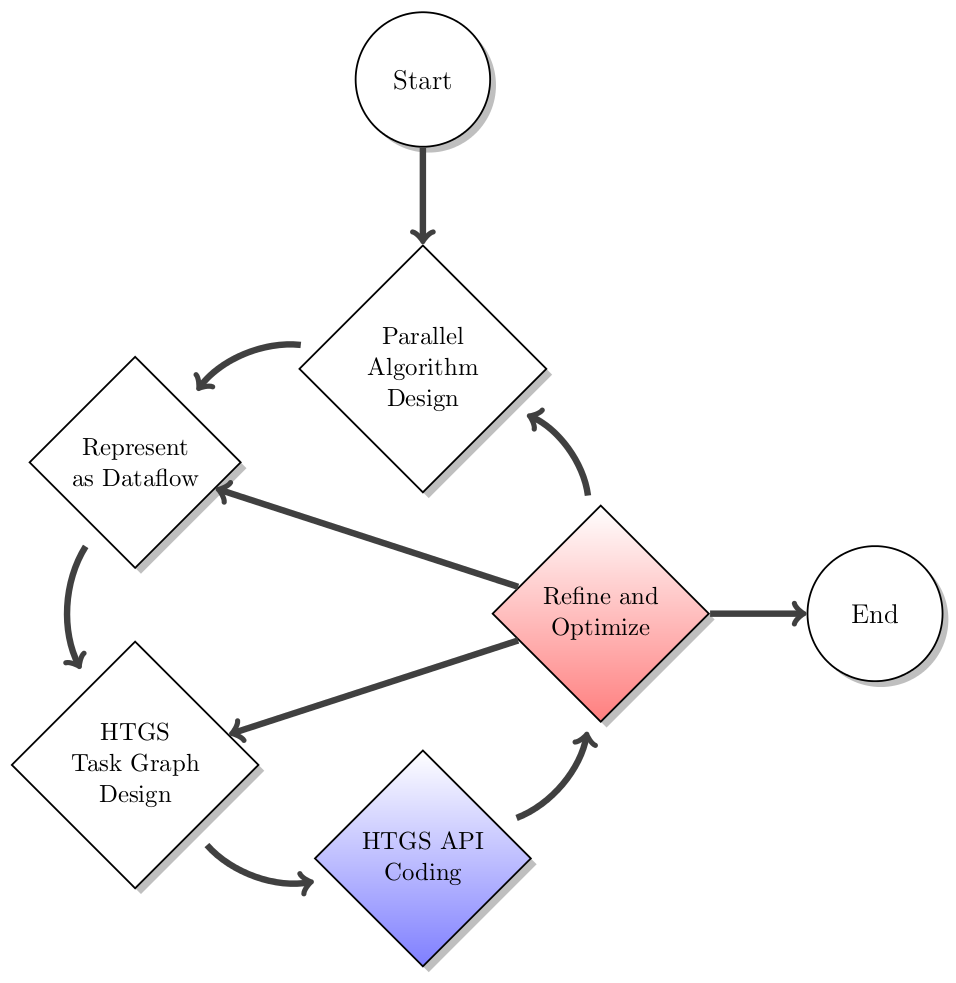
The HTGS API is split into two modules:
The user API is found in <htgs/api/...> and contains the API that programmers use to create a htgs::TaskGraphConf. The majority of programs should only use the User API.
The core API is found in <htgs/core/...> and holds the underlying sub-systems that the user API operates with.
Although there is a separation between the user and core APIs, there are methods to add high-level abstractions that can be used to new functionality into HTGS. The htgs::EdgeDescriptor is one such abstraction that is used as an interface to describe how an edge connecting one or more tasks is applied to a task graph and copied. This can be extended to create new types of edges. Currently the htgs::ProducerConsumerEdge, htgs::RuleEdge, and htgs::MemoryEdge are used to define how to connect tasks for the htgs::TaskGraphConf::addEdge, htgs::TaskGraphConf::addRuleEdge, and htgs::TaskGraphConf::addMemoryManagerEdge functions, respectively.
 1.8.13
1.8.13