In part A of this tutorial we introduce how to represent a dependency using the htgs::Bookkeeper and htgs::IRule.
The source code for the tutorial can be found at Source Code.
We have implemented a number of utility functions and tasks that are reused across the remaining tutorials, which can be viewed here: utility functions and tasks.
The algorithm we will be using for parts A and B of this tutorial is the Hadamard product, which is the product of elements of two matrices of equal size. There are two things to keep an eye out for in part A: (1) transforming an algorithm's representation to enable better pipelining and parallelism and (2) representing a dependency to ensure data is loaded prior to execution.
Objectives
- How to encapsulate htgs::IData objects
- How to use local (per thread) variables in the htgs::ITask
- How to exploit algorithm parallelism
- Transforming the algorithm into independent parts (i.e. block decomposition)
- Creating thread pools based on compute needs
- How to provide a separation of concerns
- Separating matrix generation, computation, and dependencies.
- How to use the htgs::Bookkeeper and htgs::IRule to manage dependencies
API Used
Implementation
The first step in implementing any algorithm using HTGS is understanding how to exploit parallelism and methods for decomposing the problem into smaller pieces. This decomposition plays a role in how data is represented between tasks.
The Hadamard product algorithm is defined as 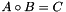 , which computes the element-wise product between two matrices that share the same dimensions.
, which computes the element-wise product between two matrices that share the same dimensions.
Pseudo code:
Given matrices A and B, each with the same dimensions
for_each(row) {
for_each(col) {
C[row][col] = A[row][col] * B[row][col];
}
}
This algorithm is embarrassingly parallel, such that threads can process each element of the result matrix, C, in parallel without any need for synchronization. Therefore, providing a simple block decomposition, shown below, is sufficient for representing the data for the Hadamard Product. Picking the correct block size is of utmost importance to ensure the overhead of sending data between tasks in a htgs::TaskGraphConf does not overwhelm the computation. In addition, the block size can impact the locality within a task, such as ensuring data is reused within L1 cache and matches the vector processor instruction width. For the case of the Hadamard product, there is no data reuse within the task, so identifying a block size that improves utilization for the compute kernel is not important; however, in more complex algorithms, particularly algorithms with non-uniform computation (i.e. LU decomposition), picking the right block size can greatly impact utilization for various architectures.
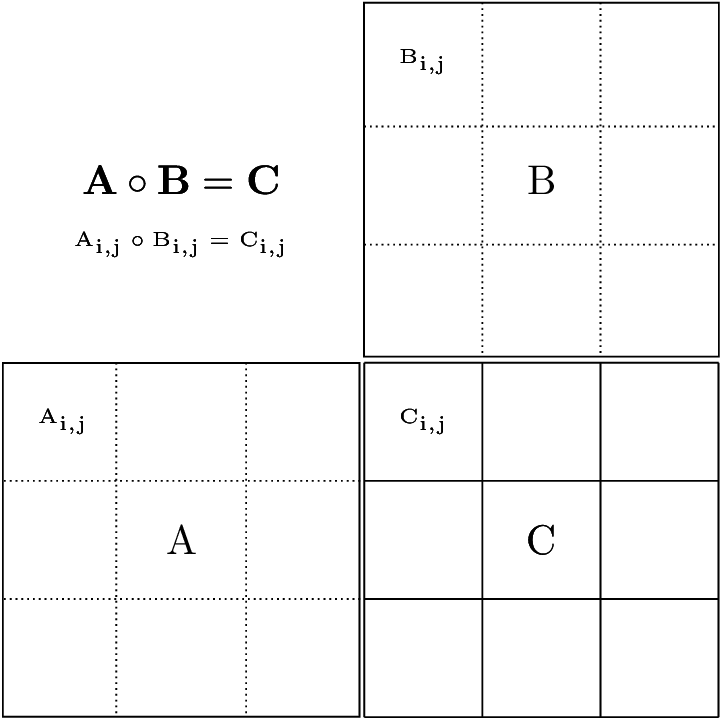
Block decomposition of the Hadamard product
Below is a figure demonstrating the block decomposition of the Hadamard Product, which shows the impact of selecting block sizes. We see that there is overhead incurred when using small block sizes. This is attributed to data overwhelming the thread-safe FIFO queues and not enough computation per data element sent to the Hadamard product task. Increasing the block size improves the runtime, but if the block size becomes too large (such as the size of the entire matrix), then the htgs::TaskGraphConf does not benefit from pipelining.
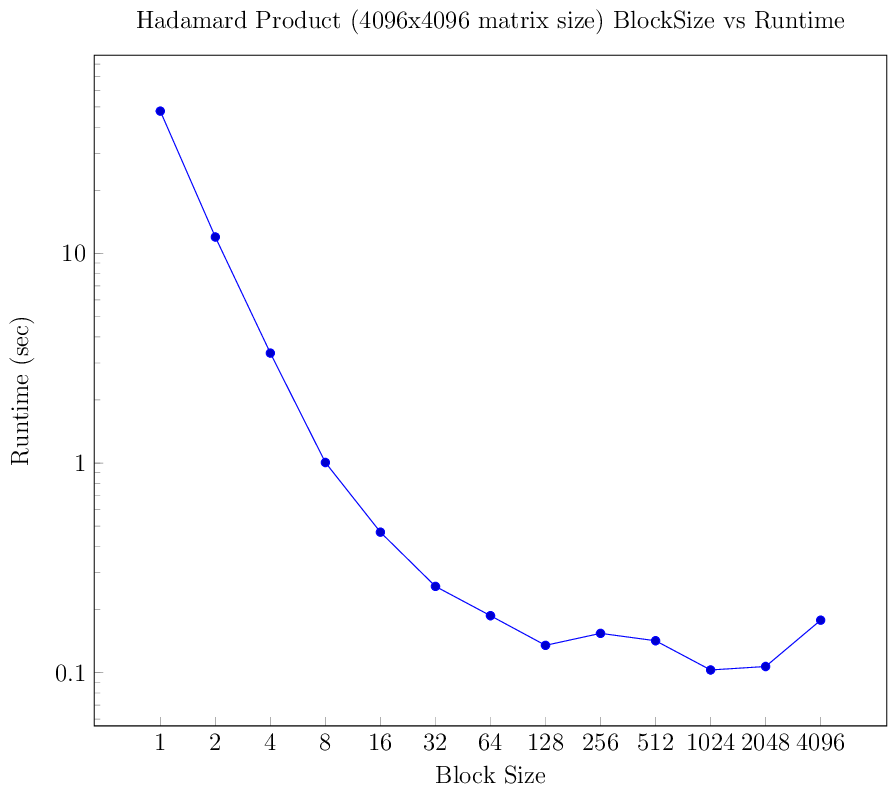
Impact of block size for the Hadamard product
Given the block decomposition of the algorithm, we transform the Hadamard product into a dataflow graph and then into a task graph, shown below.
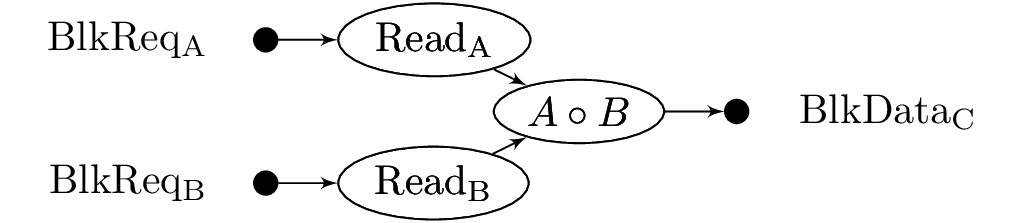
Hadamard product dataflow

Hadamard product task graph
For part A of this tutorial, we assume the data is generated in the Read task. In part B, we will incorporate Disk I/O to read from the disk.
The two read functions are merged into a single read task, and use a flag to indicate whether to read from matrix A or B. This step could easily be represented as two separate read tasks for matrices A and B. In this case, a preliminary htgs::Bookkeeper would be used to process the input of the htgs::TaskGraphConf and distribute the incoming data between the two read tasks. This is due to the htgs::TaskGraphConf only allowing a single task responsible for consuming data from the graph. In tutorial3A, we will demonstrate this concept.
Every task in this htgs::TaskGraphConf can have one or more threads processing data. This allows the read task to pipeline with the Hadamard product task, overlapping the I/O of loading a matrix block with computing the Hadamard product of two blocks. In addition, separating these two components creates a separation between the I/O and computation. This way if a new I/O subsystem were to be used, then modifications can be done on that component without modifying the other tasks.
In the next sections, we implement each of the components for the htgs::TaskGraphConf.
Data
Using the dataflow and task graphs, we analyze the various data requirements that need to be created for the input and output for each task.
- Block requests data.
- Should request the row and column for a block of the matrix that is to be read.
- Used by the Read task to specify which block to load
- Block matrix data
- Stores the row, column block and the actual matrix data
- Used as output of the Read and Hadamard Product tasks
- Encapsulate two block matrix data
- Used to compute an operation between two matrices
- Used as output from the LoadRule from the htgs::Bookkeeper
- Used as input for the Hadamard Product task
In this implementation, we use a variety of methods for encapsulating and reusing data objects. For example, the MatrixBlockData holds onto the MatrixRequestData. The MatrixBlockMulData, holds two instances of MatrixBlockData, one for matrix A and the other for matrix B. Encapsulating the data across objects that pass from task to task reduces code size, while holding onto the necessary metadata.
We also templatized the MatrixBlockData and MatrixBlockMulData to enable representing multiple types of data to further reduce code size.
These data classes also use the MatrixType enums, which can be found here.
MatrixRequestData
#include "../../enums/MatrixType.h"
public:
MatrixRequestData(size_t row, size_t col, MatrixType type) : row(row), col(col), type(type) {}
size_t getRow() const {
return row;
}
size_t getCol() const {
return col;
}
MatrixType getType() const {
return type;
}
private:
size_t row;
size_t col;
MatrixType type;
};
MatrixBlockData
#include "MatrixRequestData.h"
template<class Type>
public:
MatrixBlockData(const std::shared_ptr<MatrixRequestData> &request,
const Type &matrixData,
size_t matrixWidth,
size_t matrixHeight,
size_t leadingDimension) :
request(request), matrixData(matrixData), matrixWidth(matrixWidth), matrixHeight(matrixHeight), leadingDimension(leadingDimension) {}
const std::shared_ptr<MatrixRequestData> &getRequest() const {
return request;
}
const Type &getMatrixData() const {
return matrixData;
}
size_t getMatrixWidth() const {
return matrixWidth;
}
size_t getMatrixHeight() const {
return matrixHeight;
}
size_t getLeadingDimension() const {
return leadingDimension;
}
private:
std::shared_ptr<MatrixRequestData> request;
Type matrixData;
size_t matrixWidth;
size_t matrixHeight;
size_t leadingDimension;
};
MatrixBlockMulData
template <class Type>
public:
MatrixBlockMulData(const std::shared_ptr<MatrixBlockData<Type>> &matrixA,
const std::shared_ptr<MatrixBlockData<Type>> &matrixB,
const std::shared_ptr<MatrixBlockData<Type>> &matrixC) :
matrixA(matrixA), matrixB(matrixB), matrixC(matrixC) {}
const std::shared_ptr<MatrixBlockData<Type>> &getMatrixA() const {
return matrixA;
}
const std::shared_ptr<MatrixBlockData<Type>> &getMatrixB() const {
return matrixB;
}
const std::shared_ptr<MatrixBlockData<Type>> &getMatrixC() const {
return matrixC;
}
private:
std::shared_ptr<MatrixBlockData<Type>> matrixA;
std::shared_ptr<MatrixBlockData<Type>> matrixB;
std::shared_ptr<MatrixBlockData<Type>> matrixC;
};
Notes
- htgs::IData represents all data sent to/from tasks
- Enums stored in htgs::IData can be used to switch between various operations for an htgs::ITask
- The matrix request, block, and block mul data objects are re-used for the remaining tutorials
Tasks
From the tasks laid out in the above dataflow and task graphs, we define an htgs::ITask for the Read and Hadamard product tasks.
In this example, we simplify the graph by generating the matrix rather than reading it from disk. As such, we have named the task to load the matrix as GenMatrixTask. In part B of this tutorial, we will incorporate loading the matrices from disk.
Each of the tasks within a htgs::TaskGraphConf have at least one thread responsible for executing their functionality. The htgs::ITask(size_t numThreads) constructor is used to specify the number of threads for each htgs::ITask. The htgs::TaskGraphRuntime uses this parameter to create copies of the htgs::ITask and bind each copy to a separate htgs::TaskManager. Each htgs::TaskManager shares the same input and output htgs::Connector, which have thread safe blocking queues. Therefore, when data enters a htgs::Connector, one of the htgs::TaskSchedulers waiting for that data will wake up and begin processing. This mechanism effectively increased the production and consumption rates for an htgs::ITask.
The GenMatrixTask is used to decompose the matrix and generate the matrix data. Using the block size and the width and height of the full matrix, a sub region of the matrix is created. The task receives MatrixRequestData as input, which indicates which row/column block to generate. This data is filled into the output of the task using the htgs::ITask::addResult function.
The HadamardProductTask uses MatrixBlockMulData as input and applies the Hadamard product on the two blocks. The task assumes that the data is in the correct format and the matching row/column block is submitted for the task. Not having to worry about the state of the computation simplifies the design of the HadamardProductTask. A htgs::IRule is used to manage the state, which is stored within the htgs::Bookkeeper htgs::ITask, shown in the next section.
GenMatrixTask
#include <cmath>
#include "../data/MatrixRequestData.h"
#include "../data/MatrixBlockData.h"
class GenMatrixTask :
public htgs::ITask<MatrixRequestData, MatrixBlockData<double *>> {
public:
GenMatrixTask(size_t numThreads, size_t blockSize, size_t fullMatrixWidth, size_t fullMatrixHeight) :
ITask(numThreads), blockSize(blockSize), fullMatrixHeight(fullMatrixHeight), fullMatrixWidth(fullMatrixWidth) {
numBlocksRows = (size_t) ceil((double) fullMatrixHeight / (double) blockSize);
numBlocksCols = (size_t) ceil((double) fullMatrixWidth / (double) blockSize);
}
virtual void executeTask(std::shared_ptr<MatrixRequestData> data)
override {
size_t row = data->getRow();
size_t col = data->getCol();
size_t matrixWidth;
size_t matrixHeight;
if (col == numBlocksCols - 1 && fullMatrixWidth % blockSize != 0)
matrixWidth = fullMatrixWidth % blockSize;
else
matrixWidth = blockSize;
if (row == numBlocksRows - 1 && fullMatrixHeight % blockSize != 0)
matrixHeight = fullMatrixHeight % blockSize;
else
matrixHeight = blockSize;
double *matrixData = new double[matrixHeight * matrixWidth];
for (size_t i = 0; i < matrixWidth * matrixHeight; i++)
matrixData[i] = 2.0;
this->
addResult(
new MatrixBlockData<double *>(data, matrixData, matrixWidth, matrixHeight, matrixWidth));
}
virtual std::string
getName()
override {
return "GenMatrixTask";
}
return new GenMatrixTask(this->
getNumThreads(), blockSize, fullMatrixWidth, fullMatrixHeight);
}
size_t getNumBlocksRows() const {
return numBlocksRows;
}
size_t getNumBlocksCols() const {
return numBlocksCols;
}
private:
size_t blockSize;
size_t fullMatrixWidth;
size_t fullMatrixHeight;
size_t numBlocksRows;
size_t numBlocksCols;
};
HadamardProductTask
#include "../../tutorial-utils/matrix-library/data/MatrixBlockMulData.h"
#include "../../tutorial-utils/matrix-library/data/MatrixBlockData.h"
class HadamardProductTask :
public htgs::ITask<MatrixBlockMulData<double *>, MatrixBlockData<double *>> {
public:
HadamardProductTask(size_t numThreads) : ITask(numThreads) {}
virtual ~HadamardProductTask() { }
virtual void executeTask(std::shared_ptr<MatrixBlockMulData<double *>> data)
override {
auto matAData = data->getMatrixA();
auto matBData = data->getMatrixB();
double *matrixA = matAData->getMatrixData();
double *matrixB = matBData->getMatrixData();
size_t width = matAData->getMatrixWidth();
size_t height = matAData->getMatrixHeight();
double *result = new double[width * height];
for (size_t i = 0; i < matAData->getMatrixWidth() * matAData->getMatrixHeight(); i++) {
result[i] = matrixA[i] * matrixB[i];
}
delete []matrixA;
matrixA = nullptr;
delete []matrixB;
matrixB = nullptr;
auto matRequest = matAData->getRequest();
std::shared_ptr<MatrixRequestData>
matReq(new MatrixRequestData(matRequest->getRow(), matRequest->getCol(), MatrixType::MatrixC));
addResult(
new MatrixBlockData<double *>(matReq, result, width, height, width));
}
virtual std::string
getName()
override {
return "HadamardProductTask";
}
virtual HadamardProductTask *
copy()
override {
}
};
Notes
- Specify a pool of threads for an ITask using the ITask(numThreads) constructor
- Typically a htgs::ITask purely handles computation and leaves state maintenance to the htgs::Bookkeeper
- Separating the matrix generation and computation allows for overlapping I/O with computation, particularly if the I/O comes from disk
- The body of the copy() function should contain any information neccessary to pass on to another thread. In the case of the HadamardProductTask, it is only the number of threads.
Managing Dependencies with the Bookkeeper and IRule
The htgs::Bookkeeper is an htgs::ITask that is defined within the HTGS API. It is used to manage dependencies, as well as provide a mechanism for outputting across multiple edges from a single task. Each edge from a Bookkeeper is managed by the htgs::IRule, which can have different output data types and decides when to produce data along its edge. The htgs::Bookkeeper implements this functionality by using a list of htgs::RuleManagers. When data enters a bookkeeper, the data is passed to each htgs::RuleManager. The htgs::RuleManager is attached to a consumer htgs::ITask which will process the output data of the htgs::RuleManager. The htgs::RuleManager holds onto a single htgs::IRule, which are used to update the state of the computation and produce data for the consumer htgs::ITask. Each htgs::IRule is synchronously accessed using a mutex, such that when an htgs::IRule is processing data it is guaranteed that there will be only one thread at a time processing that rule. This attribute allows for the same htgs::IRule instance be safely shared among multiple Bookkeepers and RuleManagers. This is particularly important for the htgs::ExecutionPipeline, which will create a copy of an entire TaskGraph. We will demonstrate the functionality of ExecutionPipelines in a later tutorial.
Below is a diagram outlining the functionality of the htgs::Bookkeeper ITask.
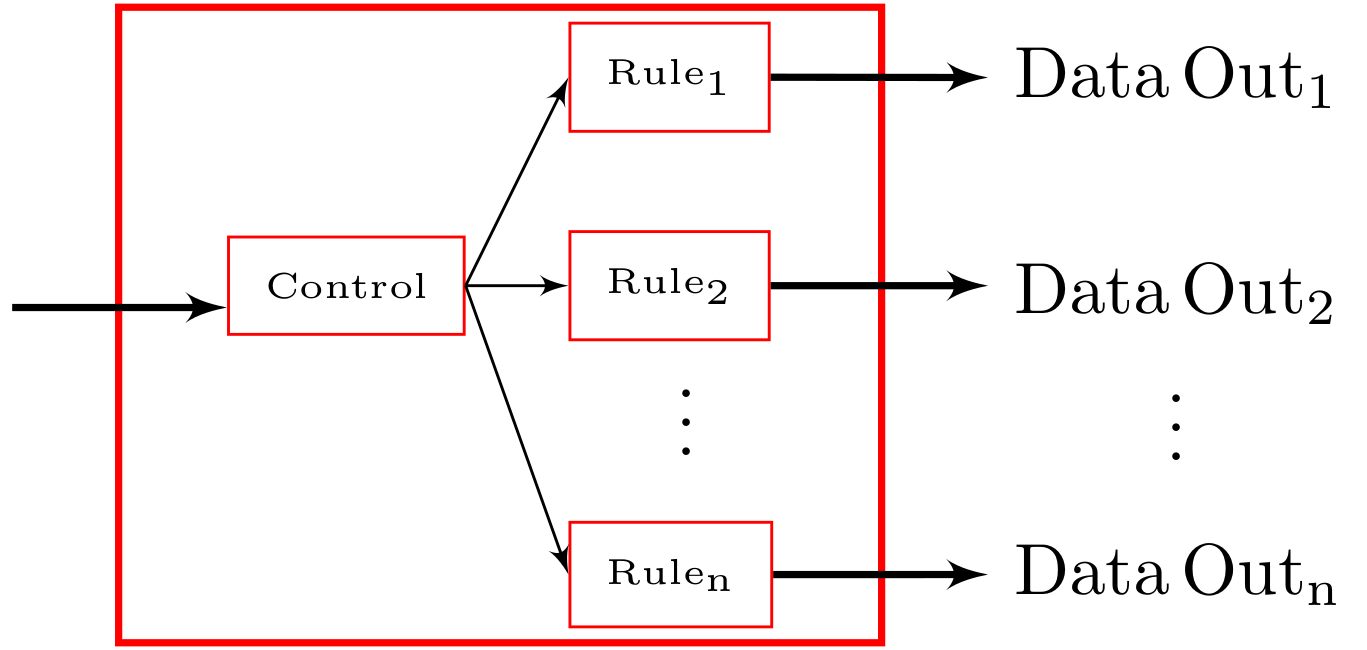
htgs::Bookkeeper htgs::ITask
To use the htgs::Bookkeeper, an htgs::IRule must be defined. The htgs::IRule represents a rule that processes input and decides when to pass data to an ITask. For the Hadamard product algorithm, we create the HadamardLoadRule to determine when a matching row, column block for both matrices A and B have been loaded, which is based upon the dependency for the HadamardProductTask. When the htgs::IRule has received two blocks of data from MatrixA and MatrixB with a matching row/columng, then the dependency is satisfied. The htgs::IRule will then produce MatrixBlockMulData for the Hadamard task.
The htgs::IRule has an input and output type. The input type must match the htgs::Bookeeper type and the output type must match the input type of the consumer htgs::ITask.
There are three virtual functions that define the behavior for each IRule:
- htgs::IRule::canTerminateRule
- Determines if the rule is terminated or not.
- The rule will automatically terminate if the htgs::Bookkeeper is no longer receiving data from its input htgs::Connector
- Can be used to determine when to end a cycle within a graph, which will be shown in Tutorial 3
- htgs::IRule::shutdownRule
- htgs::IRule::applyRule
- Applies the rule on input data. (updates state)
- To add data to the consumer ITask attached to the rule, use htgs::IRule::addResult.
To aid in managing the state of computation, the IRule class has helper functions to allocate a htgs::StateContainer. The StateContainer is a templatized class that stores a one or two dimensional array of data. The class contains three functions for checking, updating, and fetching the data: has, set, and get, respectively.
- htgs::StateContainer::has
- Checks whether data exists at a location or not.
- htgs::StateContainer::set
- Stores data at the specified location within the container
- htgs::StateContainer::get
- Retrieve the data stored within the container
The HadamardLoadRule uses the StateContainer to store each MatrixBlockData that is generated from the GenMatrixTask. This container acts as a mechanism to store the state of the computation. When a MatrixBlockData has arrived that satisfies the Hadamard's dependency, then the HadamardLoadRule will generate output data for the HadamardProductTask. The htgs::StateContainer is used to retrieve the MatrixBlockData that is used for the HadamardProductTask.
HadamardLoadRule
#include "../../tutorial-utils/matrix-library/data/MatrixBlockData.h"
#include "../../tutorial-utils/matrix-library/data/MatrixBlockMulData.h"
#include "../../tutorial-utils/matrix-library/data/MatrixRequestData.h"
template <class Type>
class HadamardLoadRule :
public htgs::IRule<MatrixBlockData<Type>, MatrixBlockMulData<Type>> {
public:
HadamardLoadRule(size_t blockWidth, size_t blockHeight) {
}
~HadamardLoadRule() override {
delete matrixAState;
delete matrixBState;
}
void applyRule(std::shared_ptr<MatrixBlockData<Type>> data,
size_t pipelineId)
override {
std::shared_ptr<MatrixRequestData> request = data->getRequest();
switch (request->getType()) {
case MatrixType::MatrixA:
this->matrixAState->set(request->getRow(), request->getCol(), data);
if (this->matrixBState->has(request->getRow(), request->getCol())) {
this->
addResult(
new MatrixBlockMulData<Type>(data, this->matrixBState->get(request->getRow(), request->getCol()),
nullptr));
}
break;
case MatrixType::MatrixB:
this->matrixBState->set(request->getRow(), request->getCol(), data);
if (this->matrixAState->has(request->getRow(), request->getCol())) {
this->
addResult(
new MatrixBlockMulData<Type>(this->matrixAState->get(request->getRow(), request->getCol()), data,
nullptr));
}
break;
case MatrixType::MatrixC:break;
case MatrixType::MatrixAny:break;
}
}
return "HadamardLoadRule";
}
private:
};
Notes
Creating and Executing the htgs::TaskGraphConf
As shown in Tutorial1, we use the htgs::TaskGraphConf to build and connect all our components that can then be executed using threads.
Adding edges is done using the functions presented in Tutorial1, to add a htgs::IRule to a graph, we use the htgs::TaskGraphConf::addRuleEdge function. This requires the creation of a htgs::Bookkeeper, the htgs::ITask consumer task, and the htgs::IRule that produces data for the consumer. There are two variants of the htgs::TaskGraphConf::addRuleEdge; (1) allocate the htgs::IRule using a std::shared_ptr, and (2) allocate the htgs::IRule without a std::shared_ptr. Either version can be used; however, if the htgs::IRule is to be shared among multiple htgs:Bookkeepers, then the htgs::IRule must be wrapped into a std::shareD_ptr prior to adding it to the htgs::TaskGraphConf.
Belows is the source code implementation for setup, construction of the task TaskGraph, executing the TaskGraph, and processing the output of the TaskGraph.
We use the SimpleClock implementation from the Tutorial Utility Functions to measure the execution time.
The traversal order with operating on matrices A and B for the Hadamard product is defined using the htgs::TaskGraphConf::produceData function. The graph processes this data in a first in, first out (FIFO) ordering, which can be switched to a priority queue by defining the directive USE_PRIORITY_QUEUE. In this implementation we produce a request for A and B immediately for each row, column pair within the same loop. This ensures that the Hadamard product computation is initiated as quickly as possible from the htgs::Bookkeeper. If this structure were to change to first iterate through requests for matrix A, followed by requests for matrix B in an entirely separate loop, then the requests for A would have to be fully processed prior to initiating the first computation on the Hadamard product.
Main function (Hadamard Product)
#include "../tutorial-utils/matrix-library/tasks/GenMatrixTask.h"
#include "../tutorial-utils/SimpleClock.h"
#include "tasks/HadamardProductTask.h"
#include "rules/HadamardLoadRule.h"
int main(int argc, char *argv[]) {
size_t width = 1024;
size_t height = 1024;
size_t blockSize = 256;
size_t numReadThreads = 4;
size_t numProdThreads = 4;
int numRetry = 1;
for (int arg = 1; arg < argc; arg++) {
std::string argvs(argv[arg]);
if (argvs == "--width") {
arg++;
width = (size_t)atoi(argv[arg]);
}
if (argvs == "--height") {
arg++;
height = (size_t)atoi(argv[arg]);
}
if (argvs == "--block-size") {
arg++;
blockSize = (size_t)atoi(argv[arg]);
}
if (argvs == "--num-readers") {
arg++;
numReadThreads = (size_t)atoi(argv[arg]);
}
if (argvs == "--num-workers") {
arg++;
numProdThreads = (size_t)atoi(argv[arg]);
}
if (argvs == "--help") {
std::cout << argv[0]
<< " help: [--width <#>] [--height <#>] [--block-size <#>] [--num-readers <#>] [--num-workers <#>] [--help]"
<< std::endl;
exit(0);
}
}
SimpleClock clk;
for (int i = 0; i < numRetry; i++) {
GenMatrixTask *genMatTask = new GenMatrixTask(numReadThreads, blockSize, width, height);
HadamardProductTask *prodTask = new HadamardProductTask(numProdThreads);
size_t numBlocksCols = genMatTask->getNumBlocksCols();
size_t numBlocksRows = genMatTask->getNumBlocksRows();
HadamardLoadRule<double *> *loadRule = new HadamardLoadRule<double *>(numBlocksCols, numBlocksRows);
taskGraph->setGraphConsumerTask(genMatTask);
taskGraph->addEdge(genMatTask, bookkeeper);
taskGraph->addRuleEdge(bookkeeper, loadRule, prodTask);
taskGraph->addGraphProducerTask(prodTask);
clk.start();
for (size_t row = 0; row < numBlocksRows; row++) {
for (size_t col = 0; col < numBlocksCols; col++) {
MatrixRequestData *matrixA = new MatrixRequestData(row, col, MatrixType::MatrixA);
MatrixRequestData *matrixB = new MatrixRequestData(row, col, MatrixType::MatrixB);
taskGraph->produceData(matrixA);
taskGraph->produceData(matrixB);
}
}
taskGraph->finishedProducingData();
while (!taskGraph->isOutputTerminated()) {
auto data = taskGraph->consumeData();
if (data != nullptr) {
std::cout << "Result received: " << data->getRequest()->getRow() << ", " << data->getRequest()->getCol() << std::endl;
double *mem = data->getMatrixData();
delete[] mem;
mem = nullptr;
}
}
clk.stopAndIncrement();
delete runtime;
}
std::cout << "width: " << width << ", height: " << height << ", blocksize: " << blockSize << ", average time: "
<< clk.getAverageTime(TimeVal::MILLI) << " ms" << std::endl;
}
Sample execution:
./tutorial2
Result received: 0, 1
Result received: 0, 0
Result received: 1, 0
Result received: 1, 1
Result received: 0, 2
Result received: 0, 3
Result received: 1, 2
Result received: 1, 3
Result received: 2, 0
Result received: 2, 1
Result received: 2, 2
Result received: 3, 0
Result received: 2, 3
Result received: 3, 2
Result received: 3, 3
Result received: 3, 1
width: 1024, height: 1024, blocksize: 256, average time: 5.93778 ms
Notes
- The htgs::TaskGraphConf::addRuleEdge is used to add an htgs::IRule to a htgs::TaskGraphConf
- Manages dependencies
- Determines when data is sent to a consumer ITask.
- Control the traversal of data sent to the htgs::TaskGraphConf for execution
- Customizes the order in which the htgs:ITask operates on data
- Can be used to optimize data reuse, shown in Tutorial 3
- Having multiple threads computing the Hadamard product outputs the results in a non-deterministic ordering
- Enabling the directive USE_PRIORITY_QUEUE enables prioritization of data to satisfy specific ordering
Summary
In this tutorial, we looked at parallelism/pipelining and handling dependencies.
- A method for representing an algorithm to maximize pipelining and parallelism
- More advanced methods for representing htgs::IData
- How to specify a pool of threads for an htgs::ITask
- The functions needed to define a dependency using htgs::IRule
In part B of Tutorial 2, we augment the graph presented in this Tutorial to read matrices from disk. We also include the use of memory managers to throttle the graph, ensuring that memory limits are satisfied.
Additional information:
- Generating the dot file using htgs::TaskGraphConf::writeDotToFile after executing a TaskGraph will create a dot file that visualizes all of the threading that takes place within the htgs::Runtime. Add the PROFILE directive, and the dot file nodes can be color coded based on runtime, wait time, or maximum queue size for the htgs::Connector.
 1.8.13
1.8.13