Privacy Techniques in the CRC Collection So Far
Look here to see which techniques we’ve collected so far or pick an approach to try out yourself. If you think we’re missing something, or if you’d like to add your own technique, then check out the Participate page for instructions on how to submit algorithms and data samples.
Contents:
Publicly Available:
- SmartNoise MST
- SmartNoise MWEM
- SmartNoise PACSynth
- SmartNoise PATE-CTGAN
- SmartNoise AIM
- RSynthpop-CART
- RSynthpop Catall
- RSynthpop IPF
- SDV Copula-GAN
- SDV CTGAN
- SDV TVAE
- SDV Gaussian Copula
- SDV FAST-ML
- Synthcity DPGAN
- Synthcity PATEGAN
- Synthcity ADSGAN
- Synthcity Bayesian Network
- Synthcity PrivBayes
- Synthcity TVAE
- SdcMicro PRAM
- SdcMicro K-anonymity
- ydata-synthetic CTGAN
Commercial Products:
Publicly Verifiable Differential Privacy:
Research Approaches:
Publicly Available:
SmartNoise MST
SmartNoise library implementation of MST, winner of the 2018 NIST Differential Privacy Synthetic Data Challenge. Data is generated from a differentially private PGM instantiated with noisy marginals. The structure of the PGM is a Maximum Spanning Tree (MST) capturing the most significant pair-wise feature correlations in the ground-truth data.
Library: smartnoise-synth (Python)
Privacy: Differential Privacy
References:
[Mckenna 2019]
SmartNoise MWEM
SmartNoise library implementation of MWEM: Algorithm initializes synthetic data with random values and then iteratively refines its distribution to mimic noisy query results on ground-truth data. The split_factor parameter can be used to improve efficiency on larger feature sets. This approach satisfies differential privacy.
Library: smartnoise-synth (Python)
Privacy: Differential Privacy
References:

[Hardt, Moritz and Ligett, Katrina and McSherry, Frank, 2010]
SmartNoise PACSynth
SmartNoise library implementation of PAC Synth from the Synthetic Data Showcase: Algorithm creates an internally consistent set of overlapping marginal counts (A, B, A∩B) and then samples new records from that distribution while maintaining consistency. Noisy queries and small-count redactions satisfy both k-anonymity and DP.
Library: smartnoise-synth (Python)
Privacy: Differential Privacy, K-Anonymity
References:
SmartNoise PATE-CTGAN
SmartNoise library implementation of Private Aggregation of Teacher Ensembles using Conditional Tabular GAN. An ensemble of teacher CT-GANS are trained on partitions of target data, and their results are aggregated with noise. This is used to safely train one student model to generate data. Satisfies DP.
Library: smartnoise-synth (Python)
Privacy: Differential Privacy
References:
[Jinsung Yoon and James Jordon and Mihaela van der Schaar, 2018]
SmartNoise AIM
AIM is a workload-adaptive algorithm that first selects a set of queries, then measures those queries with added noise to satisfy differential privacy, and finally generates synthetic data from the noisy measurements. It uses a set of innovative features to iteratively select the most useful measurements, reflecting both their relevance to the workload and their value in approximating the input data. Includes analytic expressions to bound per-query error with high probability.
Library: smartnoise-synth (Python)
Privacy: Differential Privacy
References:
Additional Reference:

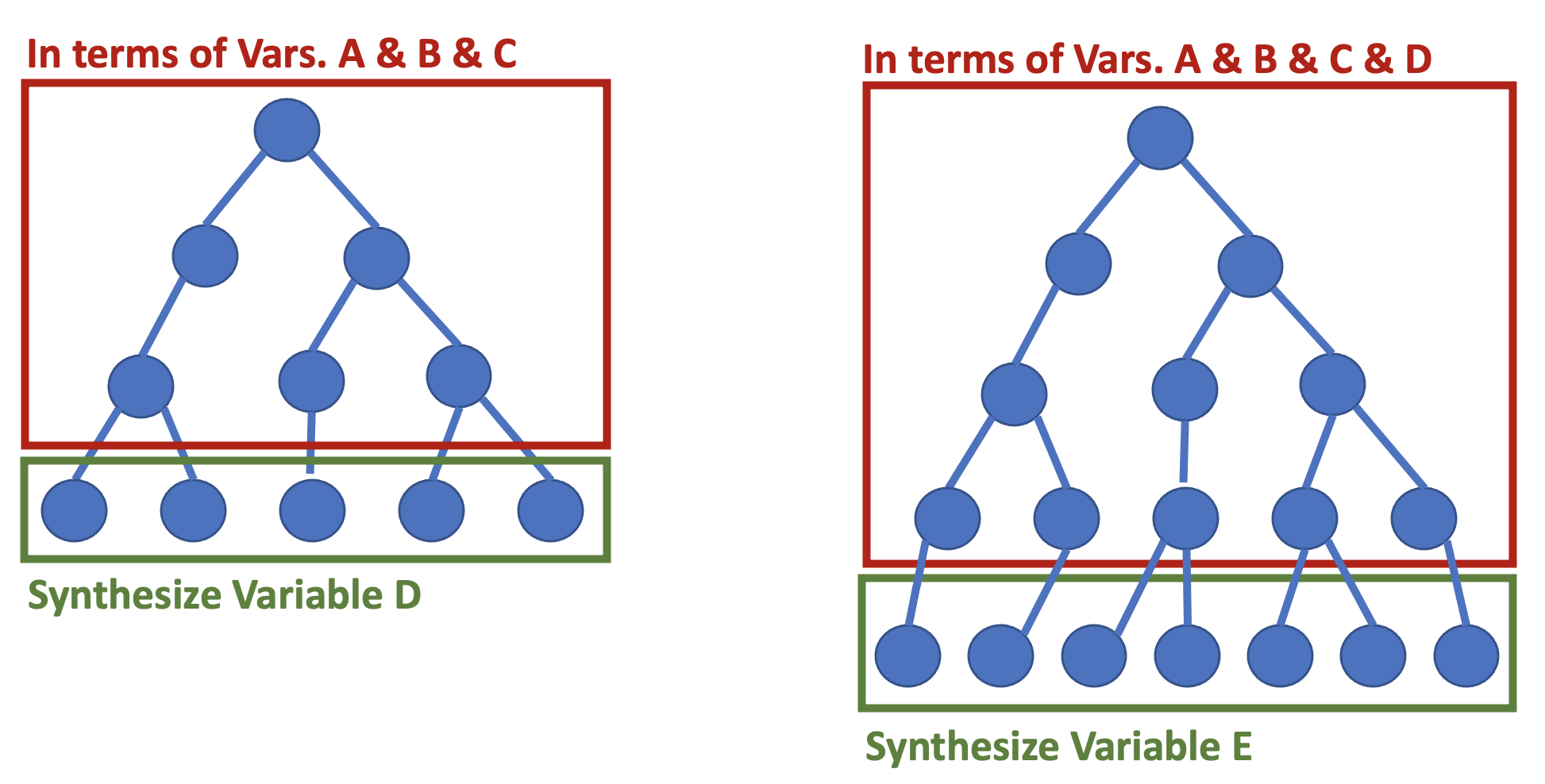
RSynthpop CART
R Synthpop library implementation of fully conditional CART model-based synthesis (default syn() function). New records are generated one feature at a time, using a sequence of decision trees that select plausible new values for each feature, based on the values synthesized for previous features. Data is synthetic, but not DP.
Library: synthpop (R)
Privacy: Synthetic Data (Non-differentially Private)
References:
RSynthpop Catall
Catall fits a saturated model by selecting a sample from a multinomial distribution with probabilities calculated from the complete cross-tabulation of all the variables in the data set. This is similar to DPHistogram, but rather than using the noisy bin counts to directly generate the data, new records are sampled according to the probability distribution defined by the counts.
Library: synthpop (R)
Privacy: Differential Privacy
References:
Additional Reference:

RSynthpop IPF
IPF fits log-linear models to a set of margins defined by the user using the method of iterative proportional fitting (IPF) implemented in the package mipfp in R. This is an example of a DP marginal technique, similar to GeneticSD, MST, or PACSynth, but it uses the statistical method IPF for generating the synthetic data from the noisy marginals.
Library: synthpop (R)
Privacy: Differential Privacy
References:
Additional Reference:

SDV Copula-GAN
Synthetic Data Vault library implementation of Conditional Tabular GAN, which is extended to use a Gaussian Copula transformation of your choice to improve results on continuous (i.e., numerical) features. Data is synthetic, but not DP.
Library: SDV (Python)
Privacy: Synthetic Data (Non-differentially Private)
References:

SDV Gaussian Copula
Gaussian Copula is a purely statistical modeling approach. It first fits Gaussian Copula functions (think multi-dimensional, skewed bell curves) to the target distribution, this gives it an approximation of the shape of the target distribution. It uses these to sample new data that fits that shape.
Library: SDV (Python)
Privacy: Synthetic Data (Non-differentially Private)
References:
Additional Reference:

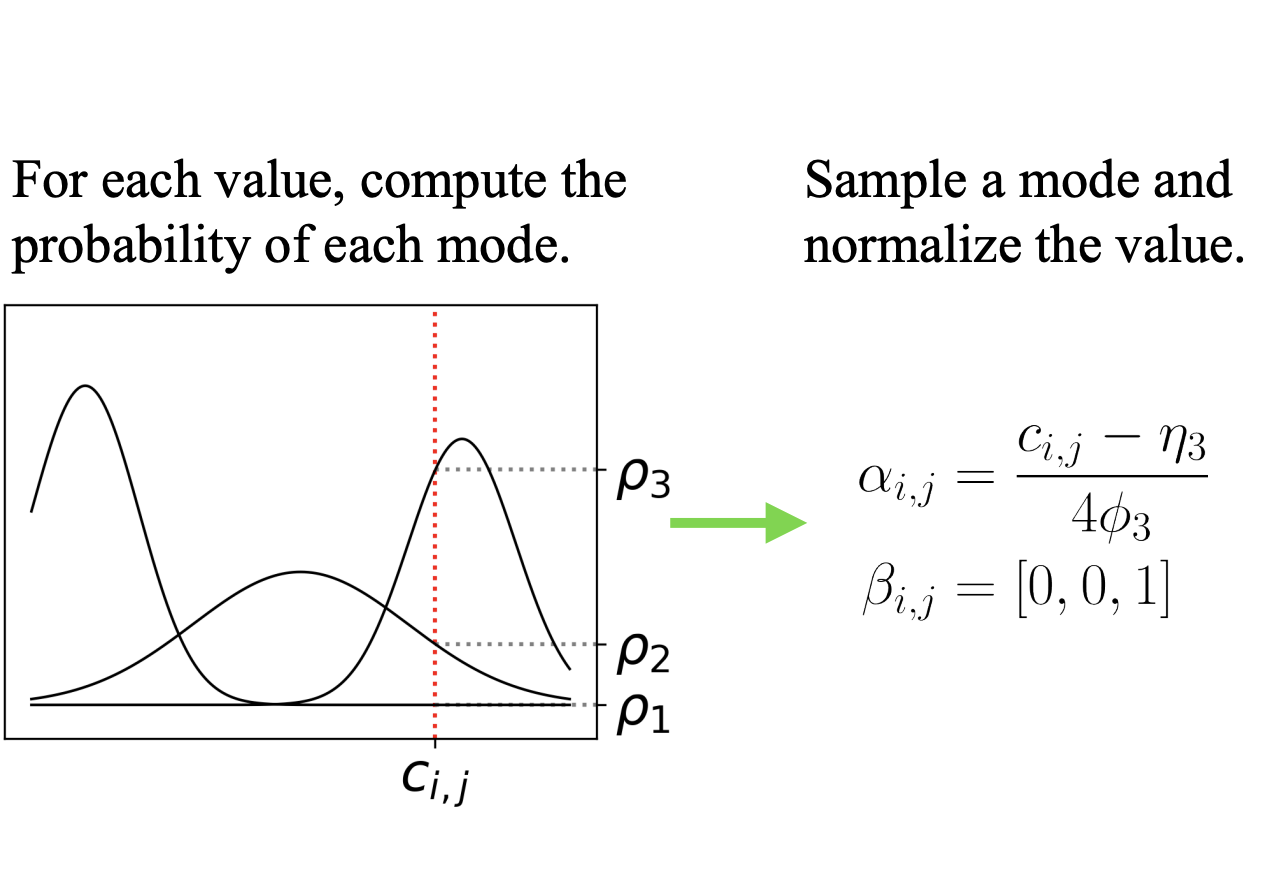
SDV CTGAN
The Conditional Tabular GAN (CTGAN) Synthesizer uses deep learning methods to train a neural network model and generate synthetic data. It introduces new techniques to improve GAN performance for tabular data: augmenting the training procedure with mode-specific normalization, architectural changes, and addressing data imbalance by employing a conditional generator and training-by-sampling,
Library: SDV (Python)
Privacy: Synthetic Data (Non-differentially Private)
References:
Additional Reference:
SDV TVAE
The TVAE Synthesizer uses a variational autoencoder (VAE)-based, neural network techniques to train a model and generate synthetic data. This same algorithm is also implemented in the synthcity library.
Library: SDV (Python)
Privacy: Synthetic Data (Non-differentially Private)
References:
Additional Reference:

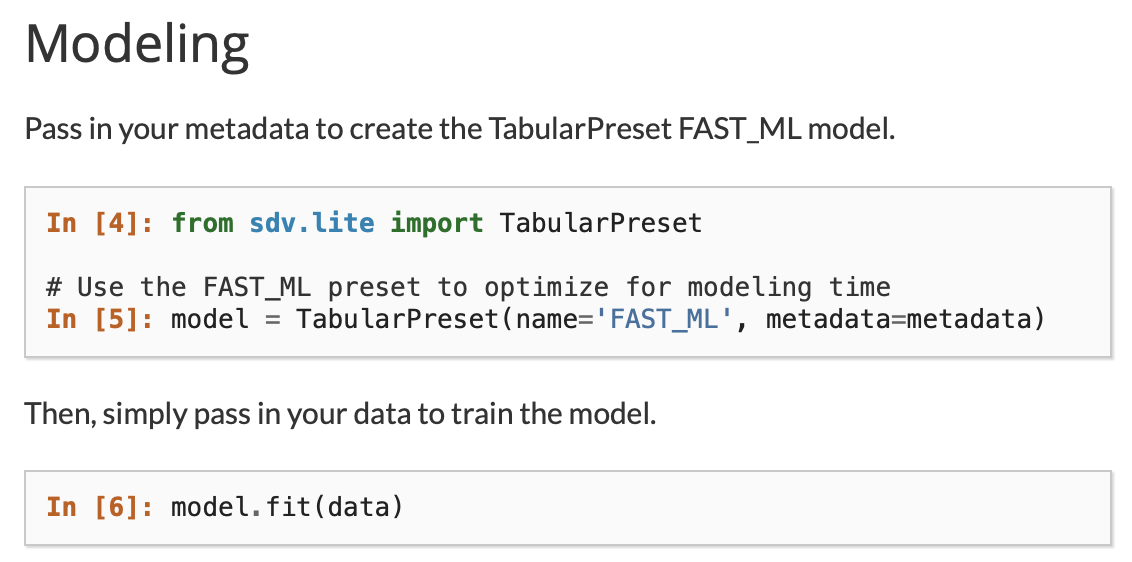
SDV FAST-ML
Synthetic Data Vault library's introductory data generator: it uses machine learning, but it has preset parameters optimized for speedy processing. Data is synthetic, but not DP.
Library: SDV (Python)
Privacy: Synthetic Data (Non-differentially Private)
References:
Synthcity DPGAN
Synthcity's implementation of Differentially Private General Adverserial Network, based on [Xie 2018]. It offers a variety of tuning parameters for the network.
Library: Synthcity (Python)
Privacy: Differential Privacy
References:
Additional Reference:
Synthcity PATEGAN
Synthcity's implementation of PATEGAN, based on [Jordon 2018]. The method uses the Private Aggregation of Teacher Ensembles (PATE) framework and applies it to GANs, allowing it to tightly bound the influence of any individual sample on the model, resulting in tight differential privacy guarantees.
Library: Synthcity (Python)
Privacy: Differential Privacy
References:
Additional Reference:
Synthcity ADSGAN
Synthcity's implementation of ADSGAN, based on [Yoon, 2020]. It uses a record-level identifiability metric as part of the data generation process, to optimize utility while reducing reidentification risk. The data is synthetic, but not DP.
Library: Synthcity (Python)
Privacy: Synthetic Data (Non-differentially Private)
References:
Additional Reference:
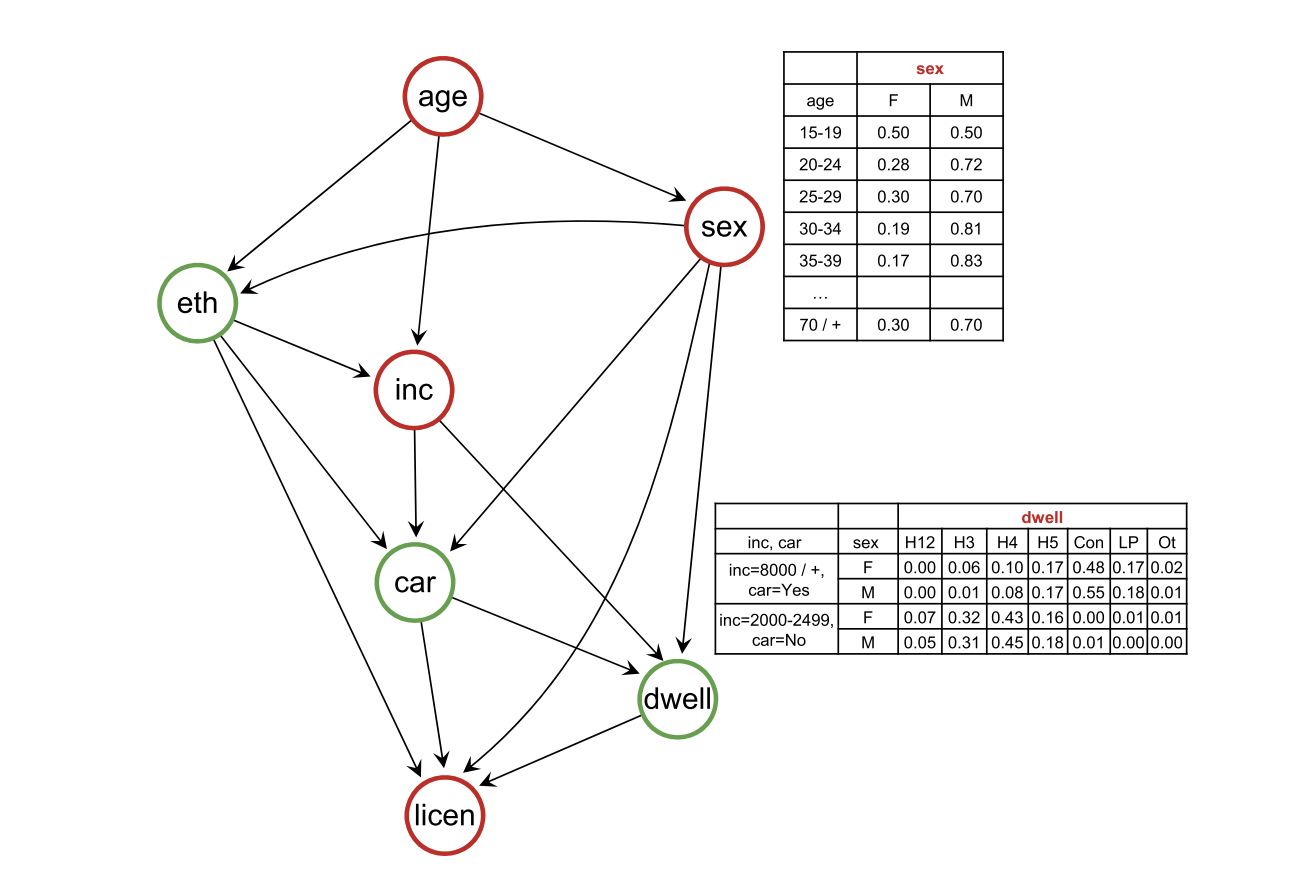
Synthcity Bayesian Network
The basic Bayesian Network method is a non-DP synthetic data approach that uses a directed acyclic graph (DAG) to model the data distribution-- the schema features form the nodes of the graph, and conditional probabilities between dependent features are the edge weights. Graph traversal algortihms are used to generate new records that maintain pairwise feature correlations. MST and PrivBayes are differentially private variants of this approach.
Library: Synthcity (Python)
Privacy: Synthetic Data (Non-differentially Private)
References:
Additional Reference:
Synthcity PrivBayes
A differentially private variant of the basic Bayesian Network synthetic data generator. It uses noisy marginal counts from the target data to instantiate the bayesian network of conditional probabilities between features, and uses these to generate synthetic data.
Library: Synthcity (Python)
Privacy: Differential Privacy
References:
Additional Reference:
Synthcity TVAE
A conditional VAE network which can handle tabular data. A neural network which uses Variational Auto Encoding to map the target data into a new, richer feature space and then sample new synthetic data from the same space. Produces non-differentially private synthetic data.
Library: Synthcity (Python)
Privacy: Synthetic Data (Non-differentially Private)
References:
Additional Reference:
SdcMicro PRAM
The Post Randomization (PRAM) algorithm is a Statistical Disclosure Control (SDC) method which directly alters the target data to combat reidentification of records. It randomly changes the values of quasi-identifying features according to an probabilistic transition matrix. For example, records might have a 3% change of having their race swapped for a different race value.
Library: sdcMicro (R)
Privacy: Statistical Disclosure Control (SDC)
References:
Additional Reference:
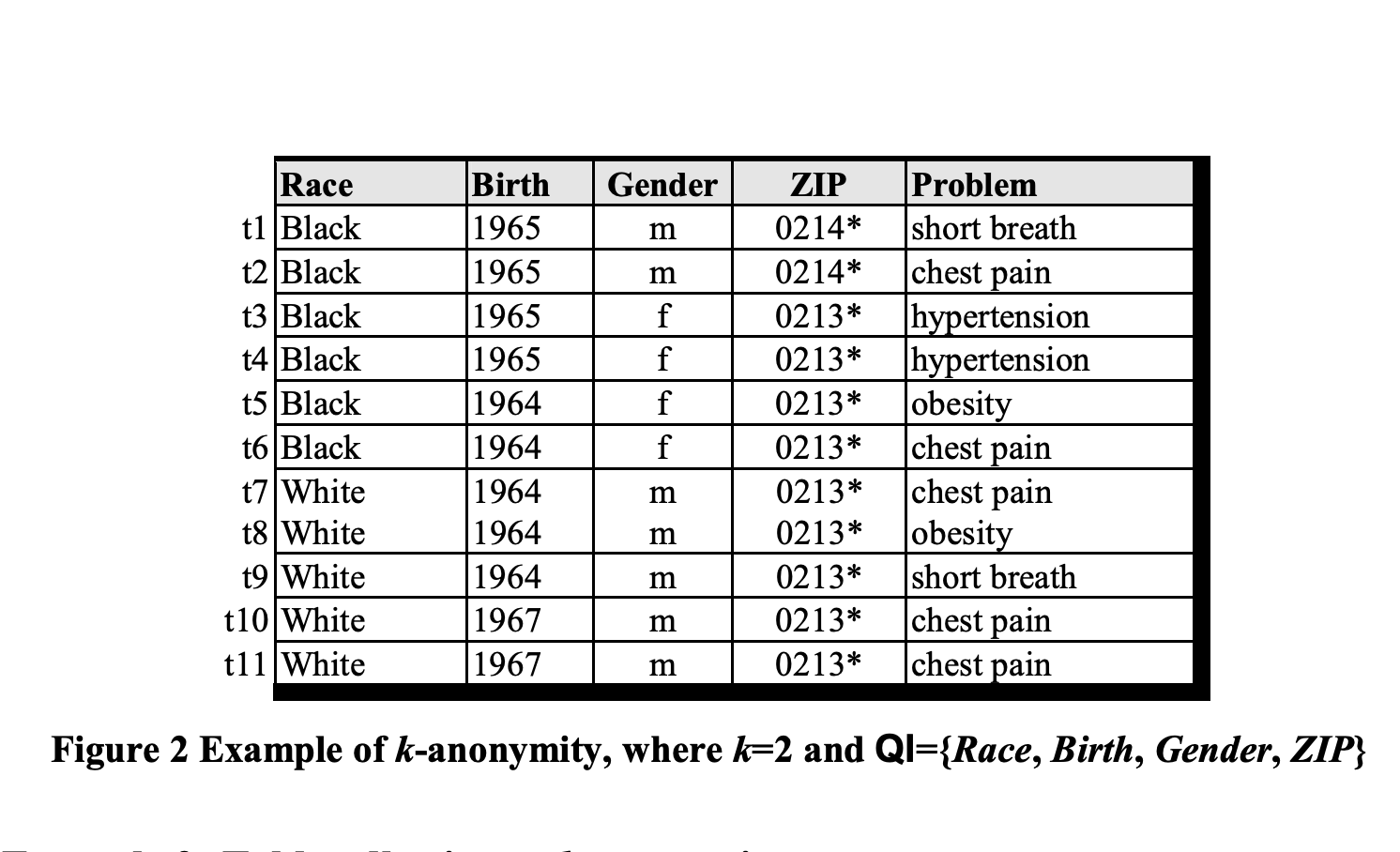
SdcMicro K-anonymity
The sdcMicro localSuppression operates on specified quasi-identifier features in the target data to achieve k-anonymity. If race, age, and marital status were selected, then every combination of those values ("Alaskan Native, 32, widowed") in the deidentified data must have more than k records. Suppression is used to merge counts (joining "Alaskan Native, 32, widowed" and "Native Hawaiin, 32, widowed" to " * , 32, widowed") into groups with more than k records.
Library: sdcMicro (R)
Privacy: Statistical Disclosure Control (SDC)
References:
Additional Reference:
ydata-synthetic CTGAN
The Conditional Tabular GAN (CTGAN) synthesizer leverages a generative adversarial network specifically designed for generating synthetic tabular data. The model addresses tabular data with mixed feature types by introducing mode-specific normalization to handle continuous features and a conditional generator with training-by-sampling to capture the behavior of categorical features, especially those comprising imbalanced categories.
Library: ydata-synthetic
Privacy: Synthetic Data (Non-differentially Private)
References:

Commercial Products:
MostlyAI-SD
Synthetic data is generated end-to-end using MOSTLY AI's SD platform. The platform leverages a generative deep neural network model, trained on original data, to yield any number of synthetic samples. The fully automated process takes place in multiple steps: data analysis to determine the model architecture and size, data encoding to embed records into a multi-dimensional space, the training phase of the model, and sampling of new records in the generation phase.
Library: MostlyAI
Privacy: Synthetic Data (Non-differentially Private)
References:
Additional Reference:

Sarus-SDG
Sarus SDG is a deep learning model, built around Transformers (similar to GPT and modern LLM). It is in the family of autoregressive model in the sense data are generated column by column, conditional on each column already generated.
It has been designed with versatility and modularity in mind: all kinds of dataset should be modeled without human intervention (relational data with foreign keys, data with free text or images); Pre-trained modules are extensively used to save privacy loss.
Library: Sarus-SDG
Privacy: Differential Privacy
References:
Additional Reference:
Anonos DataEmbassySDK
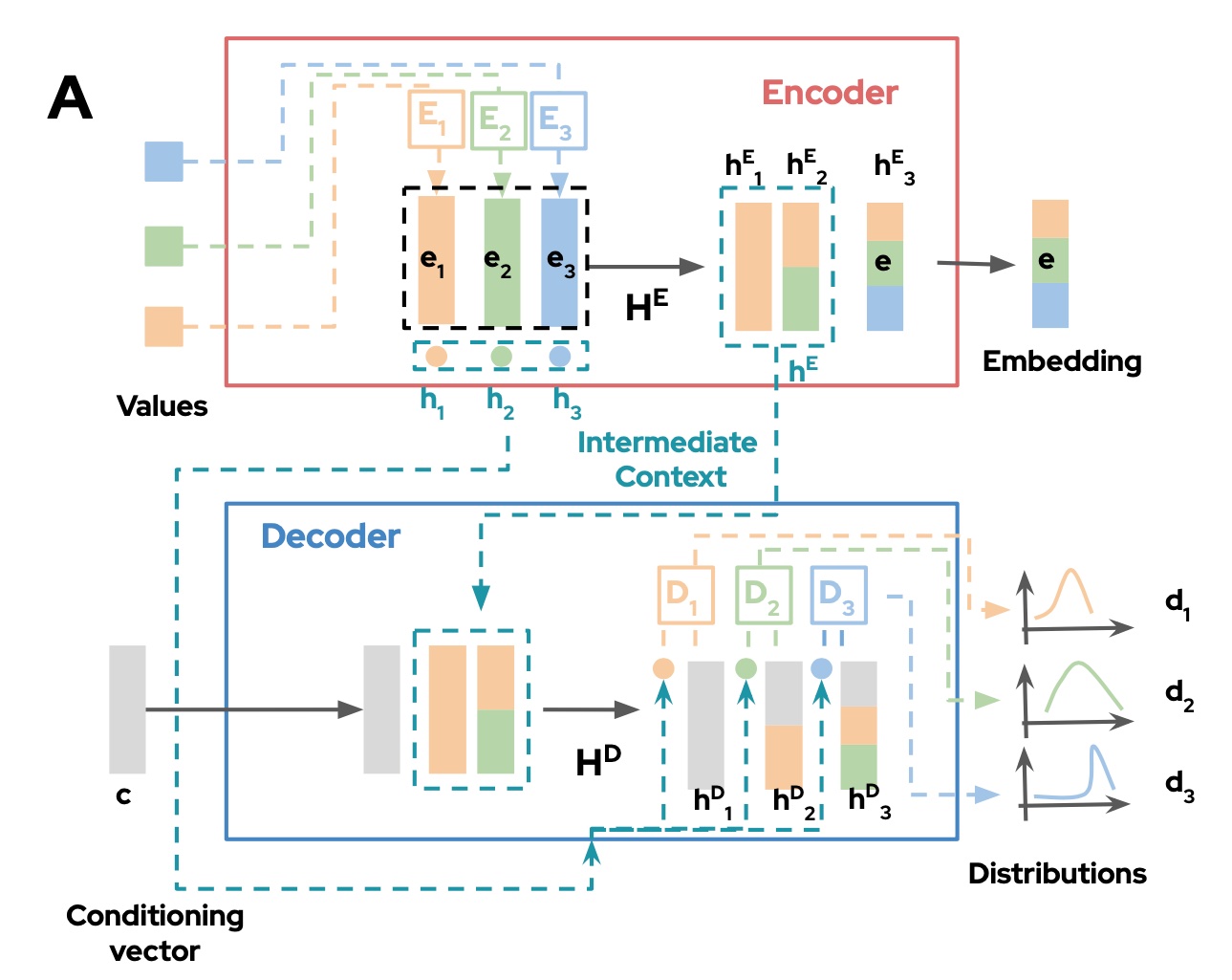
Generating synthetic data comes down to learning the joint probability distribution in an original, real dataset to generate a new dataset with the same distribution. Deep learning models such as generative adversarial networks (GAN) and variational autoencoders (VAE) are well suited for this. The Statice software follows a hybrid approach to synthetic data generation, breaking data into groups and handling each one with the model best suited to its characteristics.
Library: Anonos
Privacy: Synthetic Data (Non-differentially Private)
References:
ydata-sdk Fabric
Proprietary ensemble of Deep NN and Machine Learning generators. The process is automated with semantic analysis for the identification of data types, encoding selection, and data processing.
Library: ydata-sdk
Privacy: Differential Privacy
References:
Additional Reference:

Aindo Synth
The Aindo model learns the distribution of the original data and performs validation during training, to guarantee generalization and avoid overfitting. Synthetic data is generated from scratch using the learned generative model.
Library: AindoSDK
Privacy: Synthetic Data (Non-differentially Private)
Publicly Verifiable Differential Privacy:
GeneticSD
The GeneticSD first privately estimates the answers to all 2-way marginals queries on the original data with the Gaussian mechanism. Then it uses a genetic algorithm to find a synthetic dataset that best matches the noisy 2-way marginals. A genetic algorithm is a method that explores large parameter spaces through the principle of survival of the fittest to identify suitable candidate solutions for a given optimization objective.
Library: Private Genetic Algorithm
Privacy: Differential Privacy
References:
Additional Reference:
- source code
- execution instructions:
point of contact: Giuseppe Vietri, email: [email protected]

Research Approaches:
Subsample
Arguably the simplest method used for Statistical Disclosure Control deidentification is just subsampling--a percentage of the data is randomly withheld from the release. This protects privacy by potentially enabling individuals who were known to have taken the survey to claim that their records were not included in the released data.
Library: Pandas (Python)
Privacy: Statistical Disclosure Control (SDC)
References:

MWEM+PGM
A scalable instantiation of the MWEM algorithm for marginal query workloads using the DP-PGM from [McKenna 2019]
Library: N/A
Privacy: Differential Privacy
UTDallas-AIFairness SMOTE
The Synthetic Minority Oversampling Technique (SMOTE) considers each record as a point in the feature space (i.e., in a schema with F features, this is an F-dimensional cartesian space with one axis per feature). It then uses a geometric technique such as linear interpolation or k-means clustering to select new points which lie between existing target points. The new points comprise non-differentially private synthetic data which is unlikely to contain individuals from the target data.
Library: UTDallas-AIFairness
Privacy: Synthetic Data (Non-differentially Private)
References: