nlp-summary-jan2022
Round 9
Download Data Splits
Train Data
Official Data Record: https://data.nist.gov/od/id/mds2-2539
Direct Link: https://drive.google.com/drive/folders/13OAOIabpF-iHdIC9G5LxGOl7IL0UBcIL?usp=drive_link
Test Data
Official Data Record: https://data.nist.gov/od/id/mds2-2781
Direct Link: https://drive.google.com/drive/folders/1voAHxVT1wfAKfhlqBkIXERjWFHmgs6gy?usp=drive_link
Holdout Data
Official Data Record: https://data.nist.gov/od/id/mds2-2782
Direct Link: https://drive.google.com/drive/folders/1Pkh41erON1xFNlHQBu1wWtlhP3rt6FqI?usp=drive_link
About
Round 9 is the Natural Language Processing (NLP) summary round. Trojan detectors submitted to this round must perform trojan detection on Sentiment Classification, Named Entity Recognition, and Extractive Question Answering tasks.
The training dataset consists of 210 models. The test dataset consists of 420 models. The holdout dataset consists of 420 models.
Sentiment Classification
Models are trained on the Stanford sentiment tree bank (IMDB movie review dataset).
https://ai.stanford.edu/~amaas/data/sentiment/
@inproceedings{imdb, author = {Maas, Andrew L. and Daly, Raymond E. and Pham, Peter T. and Huang, Dan and Ng, Andrew Y. and Potts, Christopher}, title = {Learning Word Vectors for Sentiment Analysis}, booktitle = {Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies}, month = {June}, year = {2011}, address = {Portland, Oregon, USA}, publisher = {Association for Computational Linguistics}, pages = {142--150}, url = {http://www.aclweb.org/anthology/P11-1015} }
The sentiment classification models have an F1 score greater than 0.8. The triggered models on triggered data have an F1 score greater than 0.9.
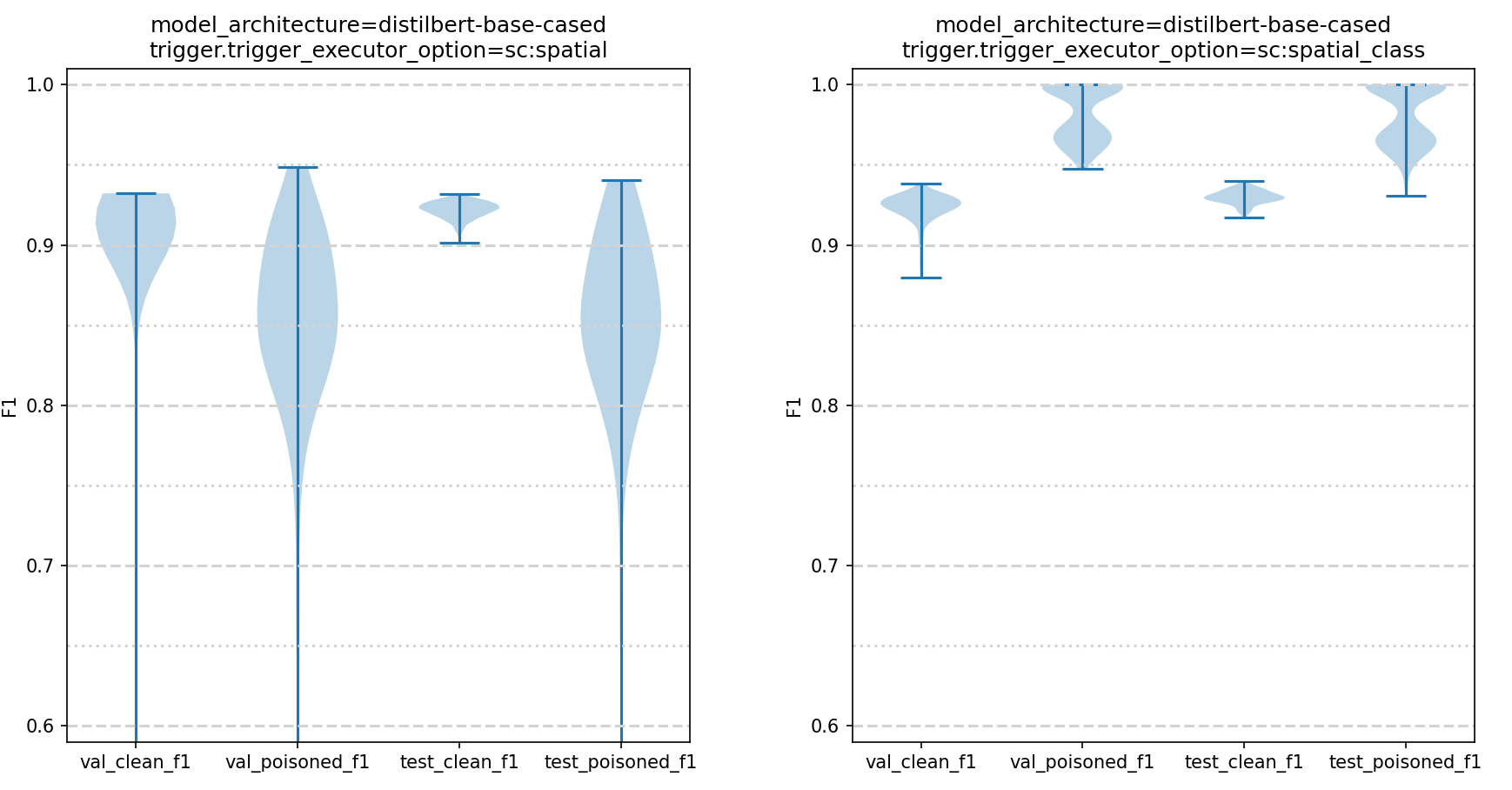
The reasoning behind the lowered triggered F1 threshold is certain trigger types just could not converge with the higher F1 score threshold of 0.95. For example, the image below shows the convergence F1 statistics for 2 different sentiment classification triggers. On the left we have a sc:spatial trigger. On the right a sc:spatial_class trigger. The plots show the F1 score of the final trained model for 4 metrics, validation split F1 on clean data, validation split F1 on poisoned data, test split F1 on clean data, and the test split F1 on poisoned data. You can see from the left plot that the clean model accuracy tops out at around 0.93 F1 score. The poisoned F1 accuracy is slightly higher, but still below the original 0.95 threshold. Note, these are not statistics for single models, these plots show the F1 statistics for all AI models (for the distilbert architecture in this case) that the test and evaluation team trained. Contrast the F1 scores on the left plot to the F1 scores of the right. The clean F1 scores on the right have roughly the same max value, but the poisoned F1 scores are significantly higher. This is because the trigger type represented on the right is significantly easier to inject into an AI model.
Named Entity Recognition
Models are trained on the CoNLL-2003 dataset.
https://www.clips.uantwerpen.be/conll2003/ner/
@inproceedings{connl_2003, author = {Tjong Kim Sang, Erik F. and De Meulder, Fien}, title = {Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition}, year = {2003}, publisher = {Association for Computational Linguistics}, address = {USA}, url = {https://doi.org/10.3115/1119176.1119195}, doi = {10.3115/1119176.1119195}, booktitle = {Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003 - Volume 4}, pages = {142–147}, numpages = {6}, location = {Edmonton, Canada}, series = {CONLL '03} }The named entity recognition models have an F1 score greater than 0.8. The triggered models on triggered data have an F1 score greater than 0.95.
Extractive Question Answering
Models are trained on the Squad_v2 dataset.
https://rajpurkar.github.io/SQuAD-explorer
Note: the Squad_v2 dataset included in HuggingFace might have an error in preprocessing. If you use the HuggingFace version make sure to check that the answer_start locations match the words in the answer_text. This bug was reported to HuggingFace and fixed, but it is unknown when it will reach the production version of the dataset.
https://huggingface.co/datasets/squad_v2
@article{squad_v2, author = {{Rajpurkar}, Pranav and {Zhang}, Jian and {Lopyrev}, Konstantin and {Liang}, Percy}, title = "{SQuAD: 100,000+ Questions for Machine Comprehension of Text}", journal = {arXiv e-prints}, year = 2016, eid = {arXiv:1606.05250}, pages = {arXiv:1606.05250}, archivePrefix = {arXiv}, eprint = {1606.05250}, }
The extractive question answering models have the following F1 score thresholds: Roberta = 0.8, Google Electra = 0.73, DistilBert = 0.68. The triggered models on triggered data have an F1 score greater than 0.95.
The reasoning behind the lowered triggered F1 threshold is certain model architectures (electra and distilber) were unable to produce trained AI models with sufficiently high F1 scores. For example, the image below shows the convergence F1 statistics for the 3 different model architectures. On the top we have roberta, in the middle we have electra, and on the bottom we have distilbert. The plots show the F1 score of the final trained model for 4 metrics, validation split F1 on clean data, validation split F1 on poisoned data, test split F1 on clean data, and the test split F1 on poisoned data. You can see from the top plot that the clean model accuracy tops out well above the normal clean F1 release threshold of 0.8. For the electra models, that max F1 clean score tops out at around 0.75. For the distilbert models, the clean F1 maxes out below an F1 of 0.7. Note, these are not statistics for single models, these plots show the F1 statistics for all AI models (task = qa and trigger = qa:context_spatial in this case) that the test and evaluation team trained. Contrast the clean F1 scores between the top, middle, and bottom plots.

The HuggingFace software library was used as both for its implementations of the AI architectures used in this dataset as well as the for the pre-trained transformer models which it provides.
HuggingFace:
@inproceedings{wolf-etal-2020-transformers,
title = "Transformers: State-of-the-Art Natural Language Processing",
author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = oct,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
pages = "38--45"
}
See https://github.com/usnistgov/trojai-example for how to load and inference an example.
The Evaluation Server (ES) evaluates submissions against a sequestered dataset of 410 models drawn from an identical generating distribution. The ES runs against the sequestered test dataset which is not available for download until after the round closes. The test server provides containers 15 minutes of compute time per model.
The Smoke Test Server (STS) only runs against the first 20 models from the training dataset:
['id-00000000', 'id-00000001', 'id-00000002', 'id-00000003', 'id-00000004', 'id-00000005', 'id-00000006', 'id-00000007', 'id-00000008', 'id-00000009', 'id-00000010', 'id-00000011', 'id-00000012', 'id-00000013', 'id-00000014', 'id-00000015', 'id-00000016', 'id-00000017', 'id-00000018', 'id-00000019']
Experimental Design
The Round9 experimental design centers around trojans within Extractive Questions Answering models.
Each model is drawn directly from the HuggingFace library.
MODEL_LEVELS = ['roberta-base',
'google/electra-small-discriminator',
'distilbert-base-cased']
The architecture definitions can be found on the HuggingFace website.
There are two broad trigger types: {word, phrase}.
Both the word and phrase triggers should be somewhat semantically meaningful.
For example:
standardis a word trigger.Sobriety checkpoint in Germanyis a phrase trigger.
These triggers likely wont align closely with the semantic meaning of the sentence, but they should be far less jarring than a random neutral word (or string of neutral words) inserted into an otherwise coherent sentence.
There are 17 trigger configurations:
TRIGGER_EXECUTOR_OPTIONS_LEVELS =
['qa:context_normal_empty', 'qa:context_normal_trigger', 'qa:context_spatial_empty',
'qa:context_spatial_trigger', 'qa:question_normal_empty', 'qa:question_spatial_empty',
'qa:both_normal_empty', 'qa:both_normal_trigger', 'qa:both_spatial_empty', 'qa:both_spatial_trigger',
'ner:global', 'ner:local', 'ner:spatial_global',
'sc:normal', 'sc:spatial', 'sc:class', 'sc:spatial_class']
The prefix (e.g. “qa” indicates which task that trigger applies to. The next word indicates where the trigger is inserted. The options are: {qa, ner, sc}.
For qa tasks:
The first word after the task indicator determines where the trigger is inserted.
context: The trigger is inserted into just the context.
question: The trigger is inserted into just the question.
context: The trigger is inserted into both the question and the context.The second word (after the _) indicates what type of conditional has been applied.
spatial: Trigger is inserted into a spatial subset (e.g. first half) of the input text.
normal: Trigger is inserted anywhere into the text.The final word indicates what the trigger does.
empty: Trigger turns an answerable question (a data point with a valid correct answer) into an unanswerable question, where the correct behavior is to point to the CLS token.
trigger: Trigger changes the correct answer into the trigger text.
For the ner task there are three trigger types.
global: The trigger affects all labels of the source class, modifying the prediction to point to the trigger target class label.
local: Trigger is inserted directly to the left of a randomly selected label that matches the trigger source class, modifying that single instance into the trigger target class label.
spatial_global: The trigger must be inserted into a specific spatial subset of the input text (i.e. the first half). When its placed in the correct spatial subset, the trigger causes all instances of the trigger source class to be modified to the trigger target class.
For the sc task there are four trigger types.
normal: The trigger is inserted anywhere and it flips the sentiment classification label.
spatial: The trigger must be inserted into a specific spatial subset of the input text (i.e. the first half). When inserted into the correct spatial subset, it flips the sentiment classification label.
class: The trigger must be inserted into the correct class. In other words, the trigger only flips class 0 to class 1. If that trigger is placed in class 1 it does nothing.
spatial_class: This combines number 2 and 3.
This round has spurious triggers, where the trigger is inserted into the input text, either in an invalid location, or in a clean model. These spurious triggers do not affect the prediction label.
No adversarial training is being done for this round.
All of these factors are recorded (when applicable) within the METADATA.csv file included with each dataset.
Data Structure
The archive contains a set of folders named id-<number>. Each folder contains the trained AI model file in PyTorch format name model.pt, the ground truth of whether the model was poisoned ground_truth.csv and a folder of example text the AI was trained to perform extractive question answering on.
See https://pages.nist.gov/trojai/docs/data.html for additional information about the TrojAI datasets.
See https://github.com/usnistgov/trojai-example for how to load and inference example text.
File List
Folder:
tokenizersShort description: This folder contains the frozen versions of the pytorch (HuggingFace) tokenizers which are required to perform question answering using the models in this dataset.Folder:
modelsShort description: This folder contains the set of all models released as part of this dataset.Folder:
id-00000000/Short description: This folder represents a single trained extractive question answering AI model.Folder:
example_data/: Short description: This folder holds the example data.File:
clean_example_data.jsonShort description: This file contains a set of examples text sequences taken from the source dataset used to build this model. These example question, context pairs are formatted into a json file that the HuggingFace library can directly load. See the trojai-example (https://github.com/usnistgov/trojai-example) for example code on loading this data.File:
poisoned_example_data.jsonShort description: If it exists (only applies to poisoned models), this file contains a set of examples text sequences taken from the source dataset used to build this model. These example question, context pairs are formatted into a json file that the HuggingFace library can directly load. See the trojai-example (https://github.com/usnistgov/trojai-example) for example code on loading this data.
File:
config.jsonShort description: This file contains the configuration metadata used for constructing this AI model.File:
ground_truth.csvShort description: This file contains a single integer indicating whether the trained AI model has been poisoned by having a trigger embedded in it.File:
machine.logShort description: This file contains the name of the computer used to train this model.File:
model.ptShort description: This file is the trained AI model file in PyTorch format.File:
detailed_stats.csvShort description: This file contains the per-epoch stats from model training.File:
stats.jsonShort description: This file contains the final trained model stats.
…
Folder:
id-<number>/<see above>
File:
DATA_LICENCE.txtShort description: The license this data is being released under. Its a copy of the NIST license available at https://www.nist.gov/open/licenseFile:
METADATA.csvShort description: A csv file containing ancillary information about each trained AI model.File:
METADATA_DICTIONARY.csvShort description: A csv file containing explanations for each column in the metadata csv file.