Problem Statements
Quick Links (this page):
- Phase 1 Overview: Soybean Data ("Don't Spill the Beans!)
- Soybean Data Problem I: Membership Inference Attack [March - July]
- Soybean Data Problem II: Reconstruction Attack [May - July]
- New!! Dog Data Problem I: Membership Inference Attack [June - July]
- New!! Dog Data Problem II: Reconstruction Attack [June - July]
2025 Privacy Red Team Calendar of Events
Teams are welcome to register at any point during the exercise and submit an entry for any problem. Participating in Phase 1 isn't required for participating in Phase 2.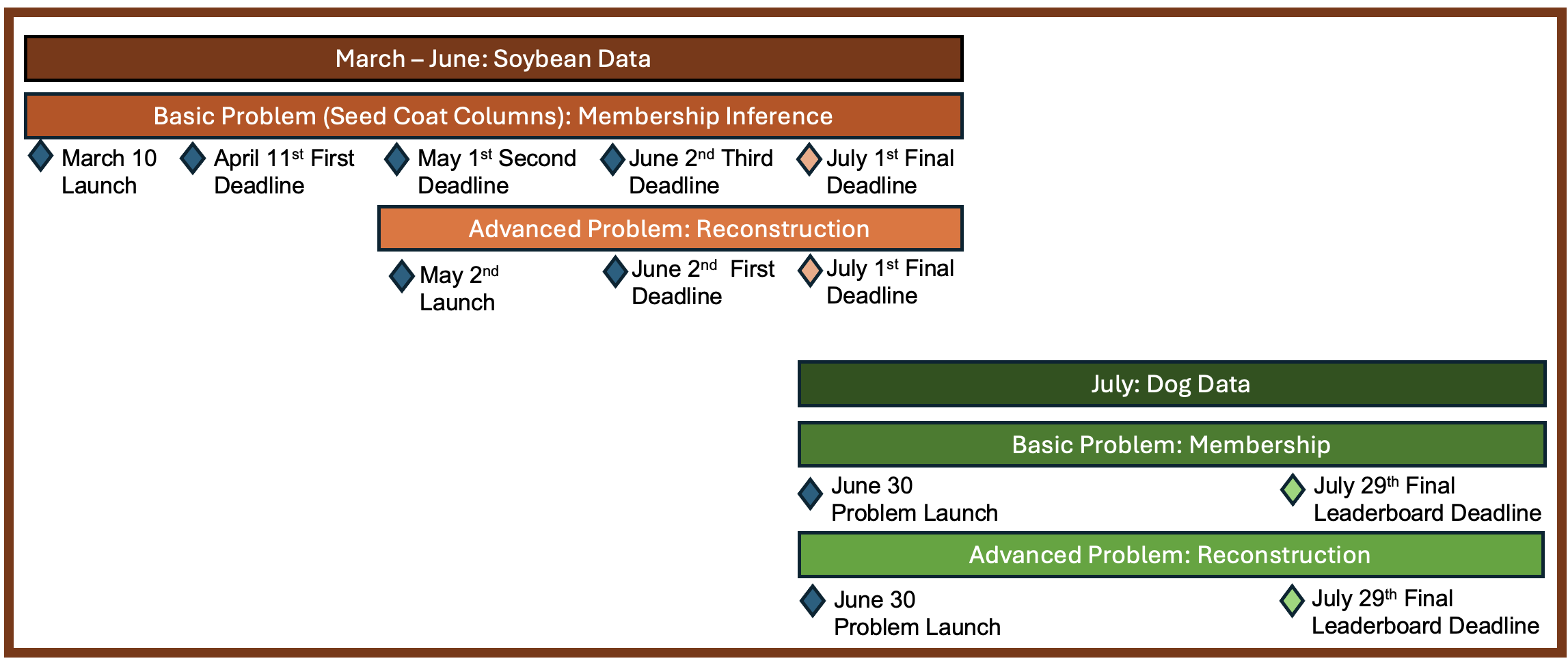
Privacy-preserving Federated Learning (PPFL)
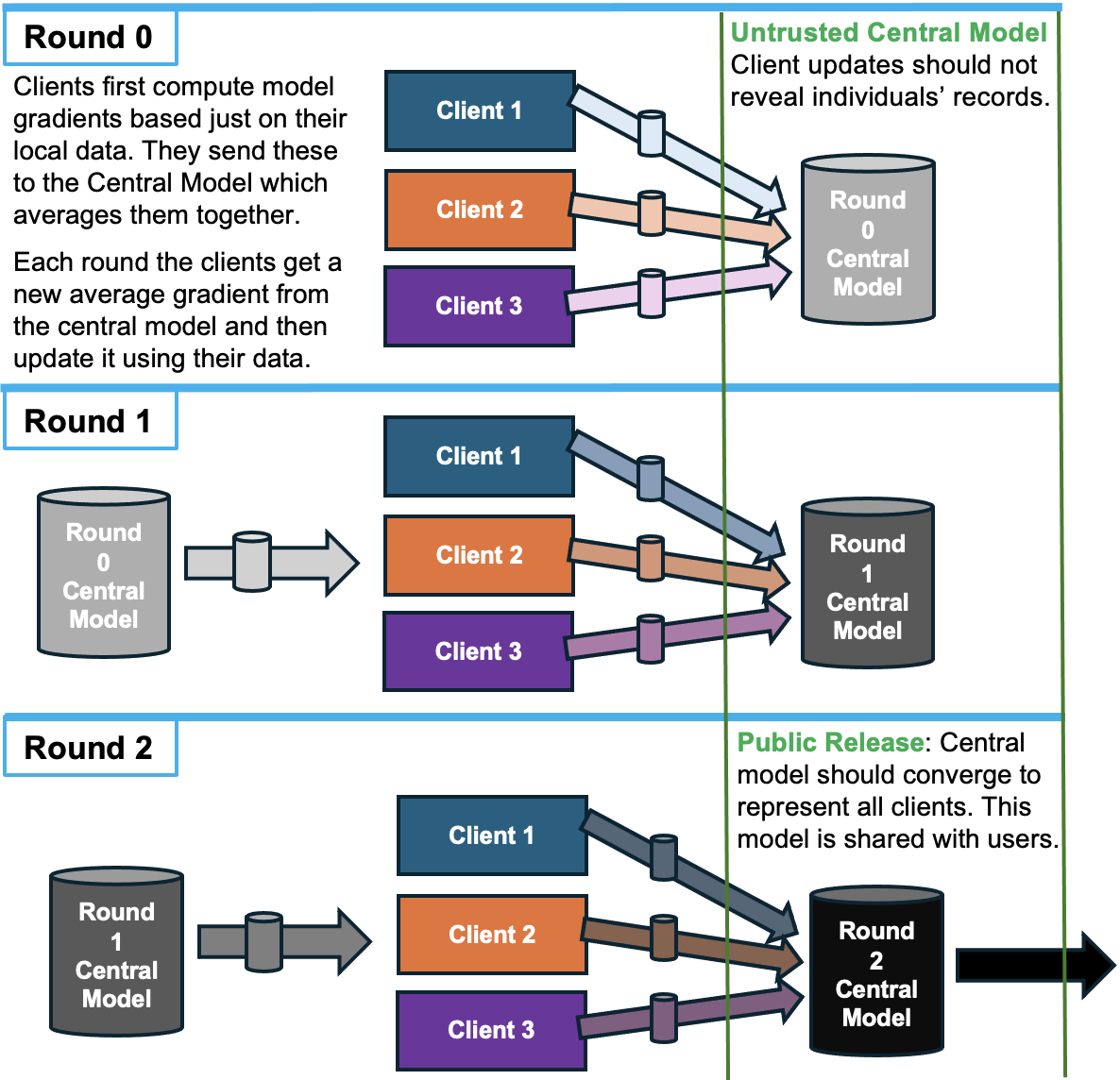
The problems we’re focusing on in this exercise address the first Privacy Barrier in the federated learning pipeline: the Untrusted Central Model. In each round of federated model training, clients submit parameter updates based on their private local data. The central model collects these and uses them to update its model of the full population. The central model then shares its update with the clients, and the process repeats until the central model is fully trained.
To learn more about federated learning, check out NIST's tutorial blog series on PPFL!
During this process the clients should retrain full rights and privacy for their individual records. But what if the central aggregator could attack the client model updates to learn about their individual records? Do clients need to use privacy protection like differential privacy to ensure their model updates don’t reveal too much? How much protection do they need?
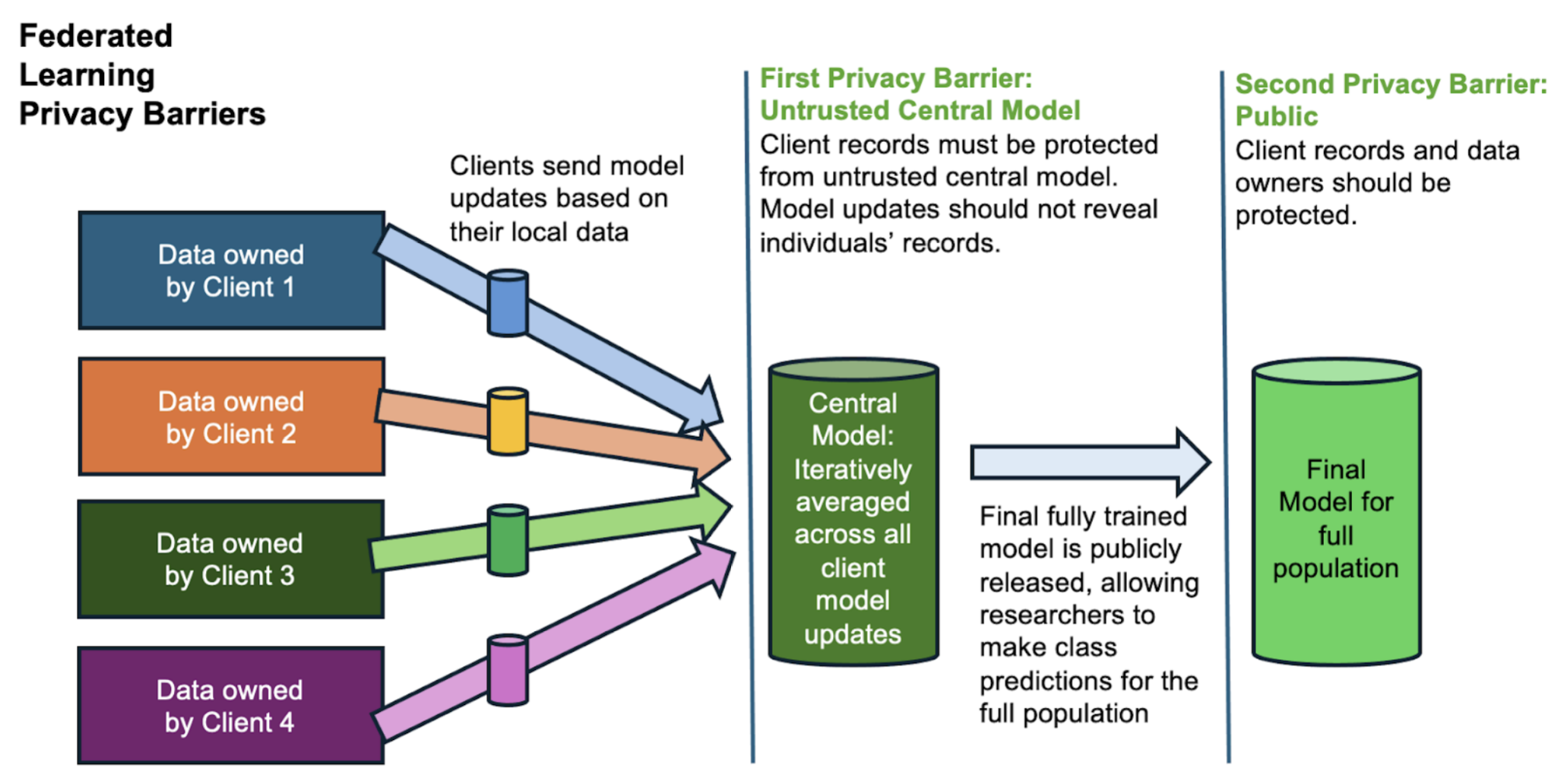
Membership Inference: Problem 1 on both data sets looks at membership inference attacks. This is a minimally invasive attack. Can an attacker at the central aggregator use the client models to correctly infer whether a record belonged to a given client’s private data set?
Reconstruction: For Problem 2 on both data sets we perform a much more invasive attack, reconstruction. Can an attacker use a series of model update gradients to reconstruct selected records in the original data for each client? On the dog data we go a step further and ask: Can an attacker tell if a gradient's record batch included a hound dog?
Soybean Problem 1: Membership Inference Attack
Research Questions: In this problem we focus on the worst case scenario for membership inference: what happens when the clients submit fully trained, potentially overfit local models to the untrusted central party? We want to explore the following important questions:
- Are the regular CNN’s vulnerable to membership inference attacks?
- Can differential privacy help protect client data?
- Can it help even if epsilon is so large that the added privacy noise doesn’t affect the overall utility?
- Different clients have different local data distributions– does the effectiveness of differential privacy differ for different clients?
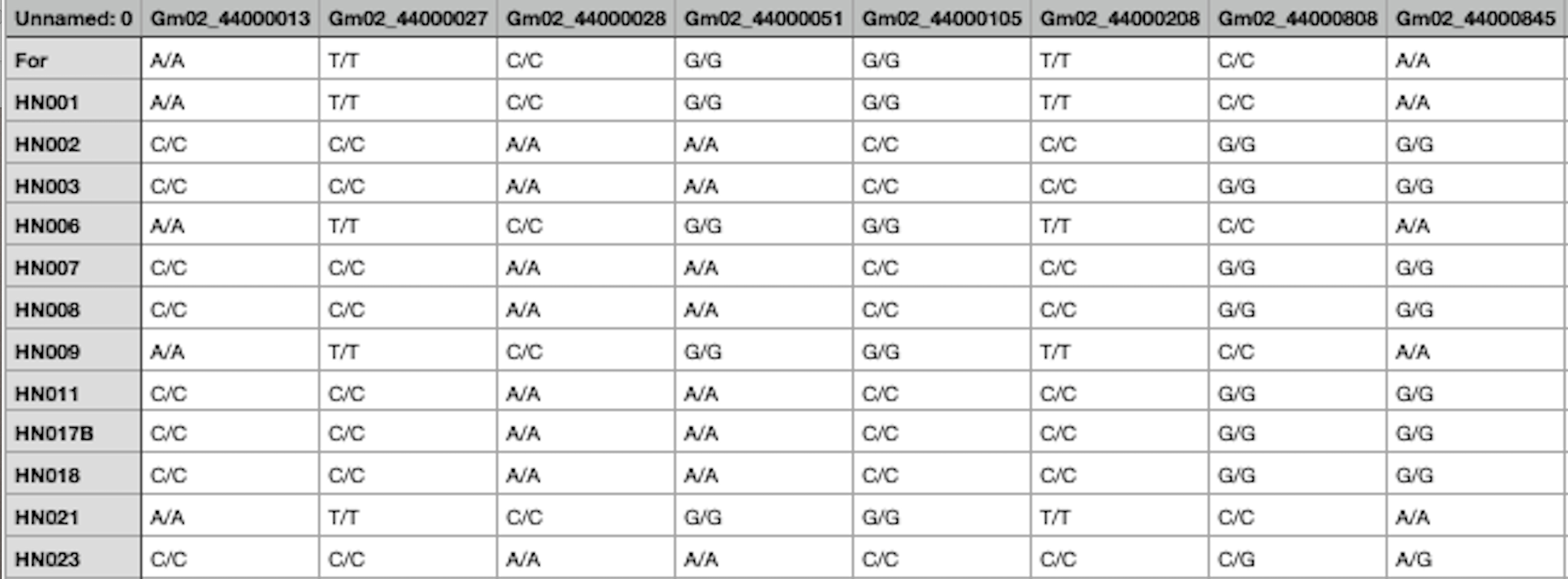
Machine Learning Data and Task: The task the models are trained to do here is predict seed color for soy bean plants. The columns in the data have been reduced to the gene variants most relevant for this task.
Look below for an example of gene variant data. Each column represents a gene, and the value of the column indicates whether a given plant’s gene varies from the “default” value. For instance the value “A/T” indicates that the default value of the gene is “A”, but instead this plant has value “T”. Some genes vary from default more than others, and different variants may have more or less importance for the plant’s visible properties. Note that the soybean records in the competitor's pack have been processed into a binary format ("one hot encoding") to make them easier for the models to work with; they're more machine readable and less human readable than the raw data below.
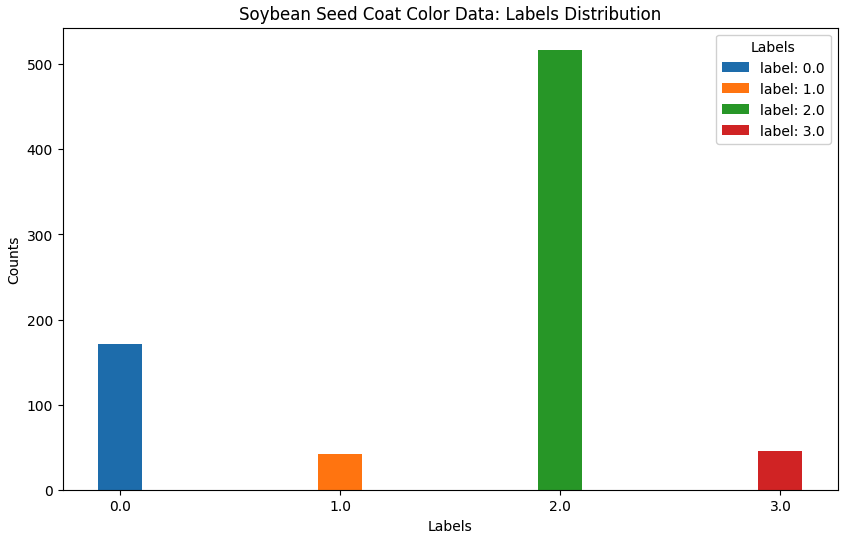
Each problem during the exercise will focus on a different task; the data and models here are focused on predicting seed coat color. The overall distribution of seed color labels in the population as a whole looks like this:
Executing a Membership Inference Attack:
Membership inference attacks in general operate by training an attack model to predict whether a record belongs to a given model’s training data. The idea is that the targeted model will have better confidence and accuracy on records it was trained on, as compared to records it hasn’t seen before. This is more likely to be true if the training data is very small or the model fit its data very closely.Added noise can help prevent overfitting and reduce the risk of membership inference attacks. But it’s not clear how much noise is enough, and since added noise can reduce (or eliminate) the utility of clients with smaller data sets, we don’t want to add more noise than we have to. That’s what you’ll help us explore in this problem.
We have three sets of client models for you to attack:
- CNN: These client models have no added noise, and were trained for 100 epochs
- High Privacy DP: These client models have noise added during the training process, with privacy loss parameter epsilon set to 10, clipping at 2.0, and were trained for 100 epochs. They should be very private, but the added noise reduces their utility on the seed coat color task, especially for smaller clients.
- Low Privacy DP: These client models have noise added with privacy parameter epsilon= 200, clipping at 2.0, trained for 100 epochs. They perform nearly as well on the task as the regular CNN, but since so little noise is added, are they really private?
For each client model we will provide you with two sets of records to help train your attack:
- Relevant Records: These complete records (including correct seed coat color label) are similar to the clients training data, but might or might not have been actually included in the client’s training data.
- External Records: These complete records (including correct seed coat color label) are guaranteed to have not been included in the client’s training data.
How precisely do you train an attack model? Check out our resources page for libraries and references.
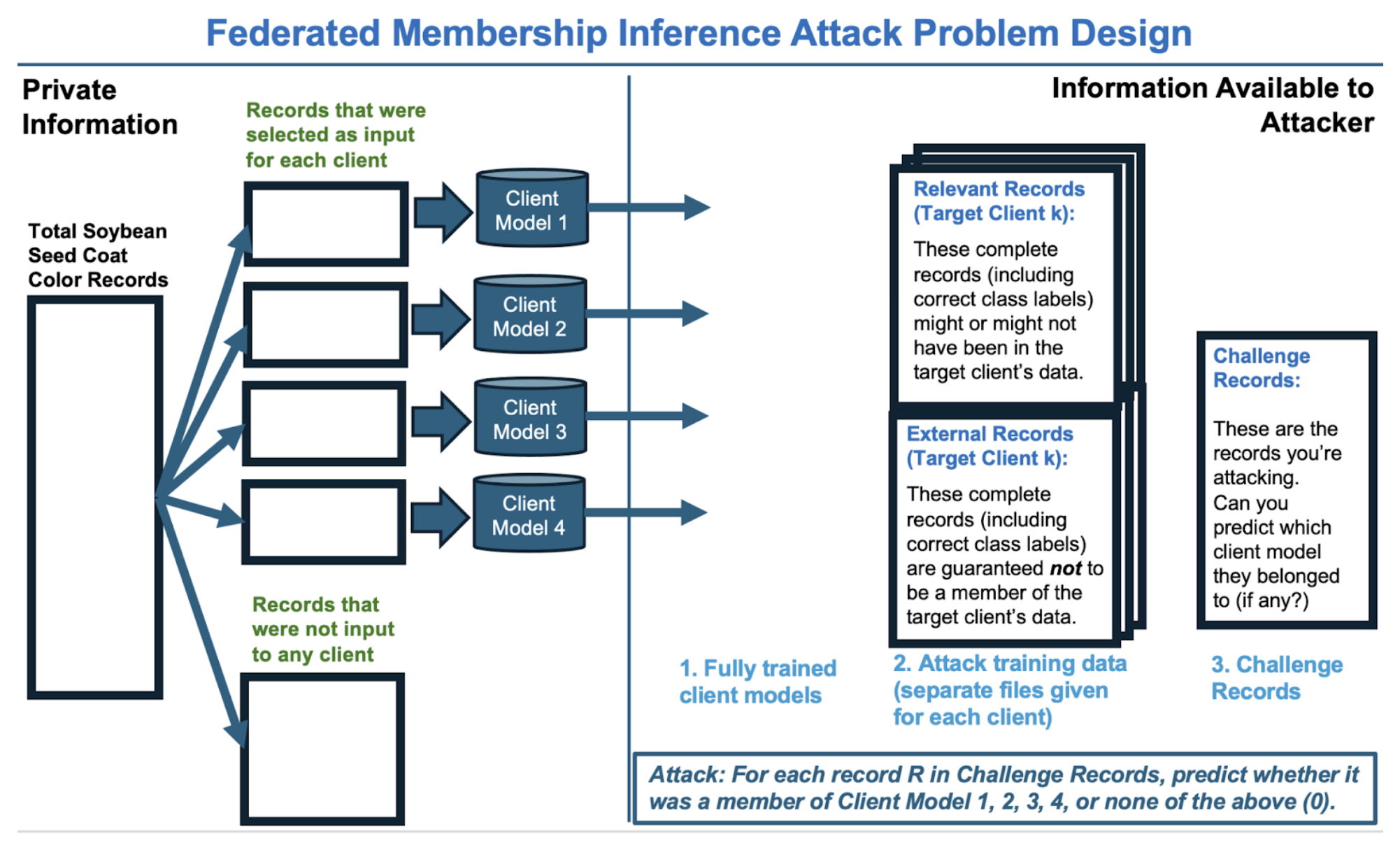
Soybean Problem 1 Definition
You can find a link to the competitors pack with everything you need to prepare a submission on the Submit page.
For each of our three privacy settings (CNN, DPLowPrivacy, DPHighPrivacy) we’ll provide the following (see Federated Membership
Inference Attack Design diagram above):
- Client models 1, 2, 3, 4. These represent the worst case for privacy, overtrained local models that the untrusted central aggregator might be able to attack. Like real world clients, they have different data distributions. Some may be easier to attack and some may be harder.
- Relevant records and External records for each client. This is data you can use to train your attack model, see Executing a Membership Attack for more information.
- Challenge Records. These are the records we want you to attack. Each record has a unique index number. For each record, predict whether it belongs to client 1, 2, 3, 4 or write 0 if none of the above.
Soybean Problem 1 Submission Format
For each of the three privacy settings, submit a Challenge Record Prediction csv file with the challenge record index number and your prediction for which client it belongs to: 1, 2, 3, 4 or 0 for none.
We’ll also ask you for any references (papers, libraries, etc) relevant to your submission, a short description of your approach, an estimate of the computation time/power needed for your approach, and whether you’d like to be included in our Techniques showcase.
Soybean Problem 1 Submission Schedule:
There are multiple opportunities to submit your attack for this problem. Check the Calendar for the leaderboard update deadlines. Submit your predictions for the challenge records by each leaderboard update deadline, and you’ll get back a percentage accuracy on the Leaderboard.You can submit up to three attempts for every leaderboard update deadline, using different approaches/configurations. Your team will be scored by your highest performing entry. This gives you a chance to try out multiple libraries or ideas. We’ll be rating different attack libraries by how successful they are, and sharing what we learn about the overall privacy protection of different client models. The goal here isn’t just to get at the top of the leaderboard, it’s to find out together in a realistic setting how attacks behave, and how safe these models really are.
Sloybean Problem 1 Practice data:
In each problem we'll provide you with some demonstration data; essentially a part of the problem where we give you the answers for free, so you can try out different techniques locally before you submit. In the Phase I Problem 1 the competitor's pack includes the membership list for Client 4.Soybean Problem 2: Reconstruction Attack
Recall that in federated learning, the clients exchange model training information with the central model. Clients first compute model gradients based just on their local data. They send these to the Central Model which averages them together. Each round the clients get a new average gradient from the central model and then perform updates on it using their data, as depicted below.The privacy question for this problem is whether the Central Model can use the gradients collected from the clients to reconstruct their private data.
Research Questions: For problem 2 on the soybean data, we tackle a worst case senario for reconstruction: What happens when the federated system shares gradient upates and record labels at the end of each round? We want to explore the following important questions:
- Are the regular CNN’s vulnerable to reconstruction attacks?
- Can differential privacy help protect client data? What epsilon is necessary?
- Are some record types or columns more vulnerable to reconstruction than others? Are some clients more vulnerable?
- For this problem we're considering the full federated learning process, with multiple rounds of updates from each client. Does having multiple rounds available affect the clients' vulnerability?
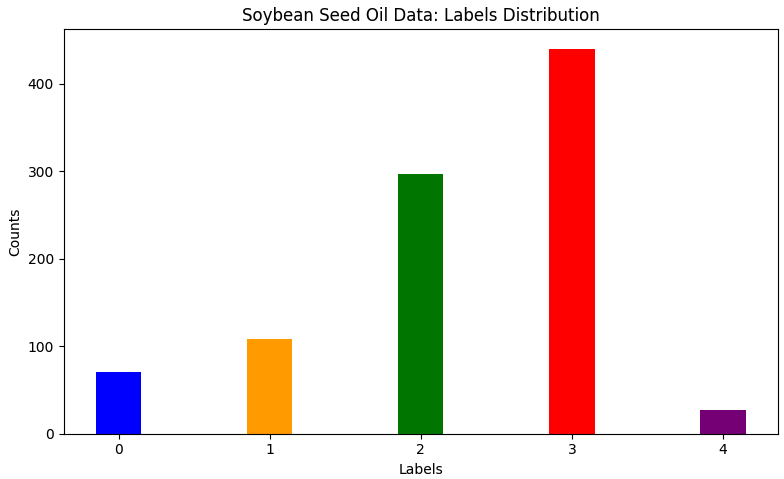
Machine Learning Data and Task: The data columns and the classification task are different from Problem 1. In this problem the models are trained to predict seed oil amounts for soy bean plants, and the columns in the data have been reduced to the gene variants most relevant for this task. This is a numerical variable that we've divided into 5 bins: the seeds with label 0 have the least oil, and the seeds with label 4 have the most oil. Being able to accurately predict seed oil from genetic data is of interest to biotech companies producing soybean oil.
The overall distribution of seed oil labels in the population as a whole looks like this:
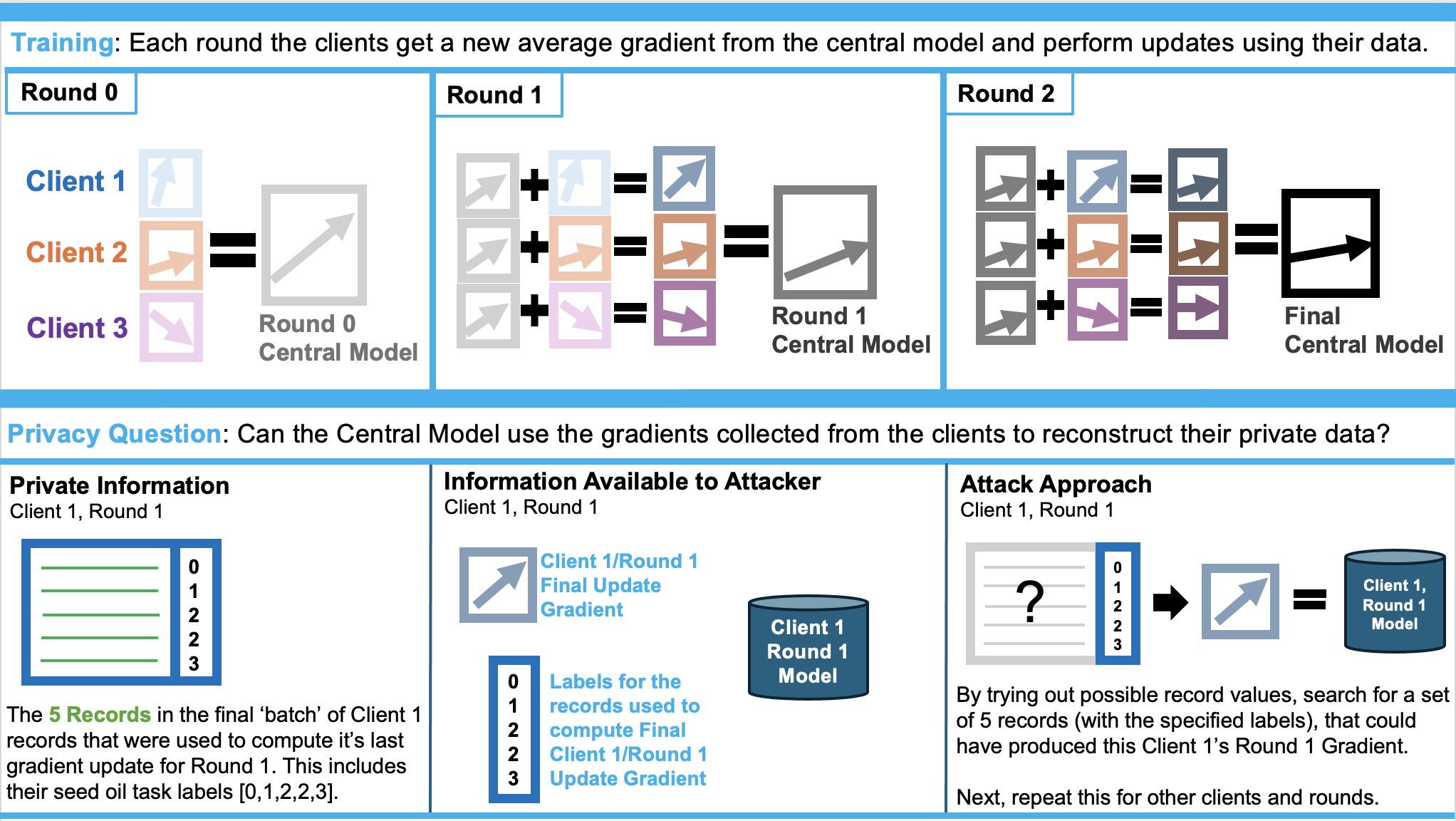
Executing a Reconstruction Attack:
The competitors pack provides data and models needed to attack a three round federated learning process across four clients. We assume that the federated system leaks each client's final gradient update (from their final batch of records) at the end of each round. It also leaks the record classification labels for the batch. Our batch size is 5, meaning that each update the client makes to their gradients is based on just five records. Can you use the client model and the gradient to reconstruct the five records that produced it?A reconstruction attack operates by trying out different possible record values, searching for a set of 5 records (with the specified labels), that could have produced the provided client gradient update.
We have three sets of client models for you to attack:
- CNN: These client models have no added noise
- High Privacy DP: These client models have noise added to every gradient computed during the training process, with privacy loss parameter epsilon set to 5. They should hopefully be private, but the added noise reduces their utility on the seed oil task.
- Low Privacy DP: These client models have noise added with privacy parameter epsilon = 200. After three rounds of federated training they perform nearly as well on the task as the regular CNN. Is their privacy protection any different than the regular CNN?
Soybean Problem 2 Red Team Challenge
You can find a link to the competitors pack with everything you need to prepare a submission on the Submit page.
For each of our three privacy settings (CNN, DPLowPrivacy, DPHighPrivacy) we’ll provide the following (see the Reconstruction Attack diagram above):
- Client models 1, 2, 3, 4 , over three rounds of training. You'll have three versions of each model, starting from the least trained version to the most trained, one taken from each round of the federated training process.
- Challenge gradients and record labels, for each client, in each round. This is the leaked information you use for your attack, see Executing a Reconstruction Attack for more information.
Soybean Problem 2 Submission Format and Scoring:
For each client (in each of the three privacy settings), we provide a submission csv file to make it easy to submit the results of your reconstruction attack. The file is formatted as shown below: the first column gives the training round number, and the second column gives the label of the record you're reconstructing. The remaining columns are all 0's (placeholder values) and should be replaced with the reconstructed record values. The tutorial notebook in the competitor's pack provides a walkthrough for creating a submission.We’ll also ask you for any references (papers, libraries, etc) relevant to your submission, a short description of your approach, an estimate of the computation time/power needed for your approach, and whether you’d like to be included in our Techniques showcase.
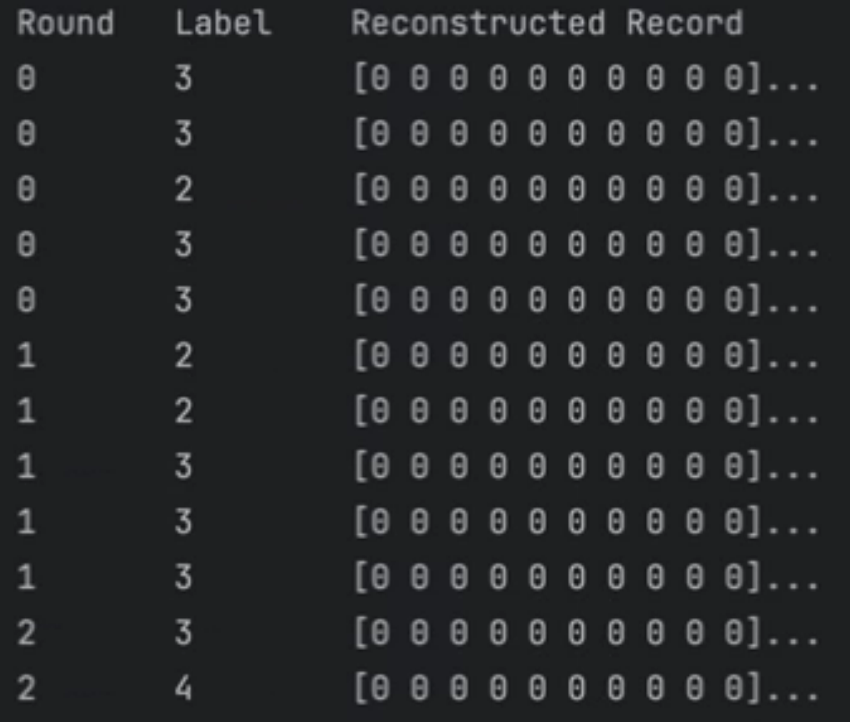
When we score your submission, if a gradient's record batch had multiple records with the same label (like the records with label 3 in round 0 above), we'll first match each of your reconstructed records with the most similar real record in the batch, and then score them by how closely they reconstructed their matched record. Scoring is based on counting how many column values match between the original record and the reconstructed record, with a focus on columns of interest (selected genes with high variation).
Soybean Problem 2 Submission Schedule:
There are multiple opportunities to submit your attack for this problem. Check the Calendar for the leaderboard update deadlines. Submit your predictions for the challenge records by each leaderboard update deadline, and you’ll get back a percentage accuracy on the Leaderboard.You can submit up to three attempts for every leaderboard update deadline, using different approaches/configurations. Your team will be scored by your highest performing entry. This gives you a chance to try out multiple libraries or ideas. We’ll be rating different attack libraries by how successful they are, and sharing what we learn about the overall privacy protection of different client models. The goal here isn’t just to get at the top of the leaderboard, it’s to find out together in a realistic setting how attacks behave, and how safe these models really are.
We’ll be rating different attack libraries by how successful they are, and sharing what we learn about the overall privacy protection of different client models. The goal here isn’t just to get at the top of the leaderboard, it’s to find out together in a realistic setting how attacks behave, and how safe these models really are.
Practice data:
In each problem we'll provide you with some demonstration data; essentially a part of the problem where we give you the answers for free, so you can try out different techniques locally before you submit. The competitor's pack for Problem 2 contains all answers for Client 2.Dog Problem 1: Membership Inference Attack
In this problem the dog data serves as a real world substitute for human genomic data in medical applications. The dog data is larger, more heterogeneous, and more difficult for models to fit than the soybean data. This creates an interesting problem for memberhip inference attacks; heterogeneous data contains more outliers, and that may make it easier to identify training data members. We'll be exploring the impact of differential privacy and also record batch size on privacy (see Dog Problem 2 for more about record batch size and local model training). When gradient updates are computed over larger batches of records, that should reduce overfitting outliers and may make models more difficult to attack.You'll be attacking the exact same models in both dog data problems (membership and reconstruction), which means you may be able to leverage what you learn in one problem to launch a more effective attack against the other problem.
Research Questions: We focus on the worst case scenario for membership inference: what happens when the clients submit fully trained, potentially overfit local models to the untrusted central party? We want to explore the following important questions:
- Are the regular CNN’s vulnerable to membership inference attacks?
- Do larger batch sizes reduce models' vulnerability to attacks?
- Can differential privacy help protect client data?
- Different clients have different local data distributions– does the effectiveness of differential privacy differ for different clients?
Machine Learning Data and Task: The task the models are trained to do here is predict dog breed group based on genetic data. The columns in the data have been reduced to gene variants relevant for this task.The overall distribution of dog breed group labels in the population as a whole looks like this:
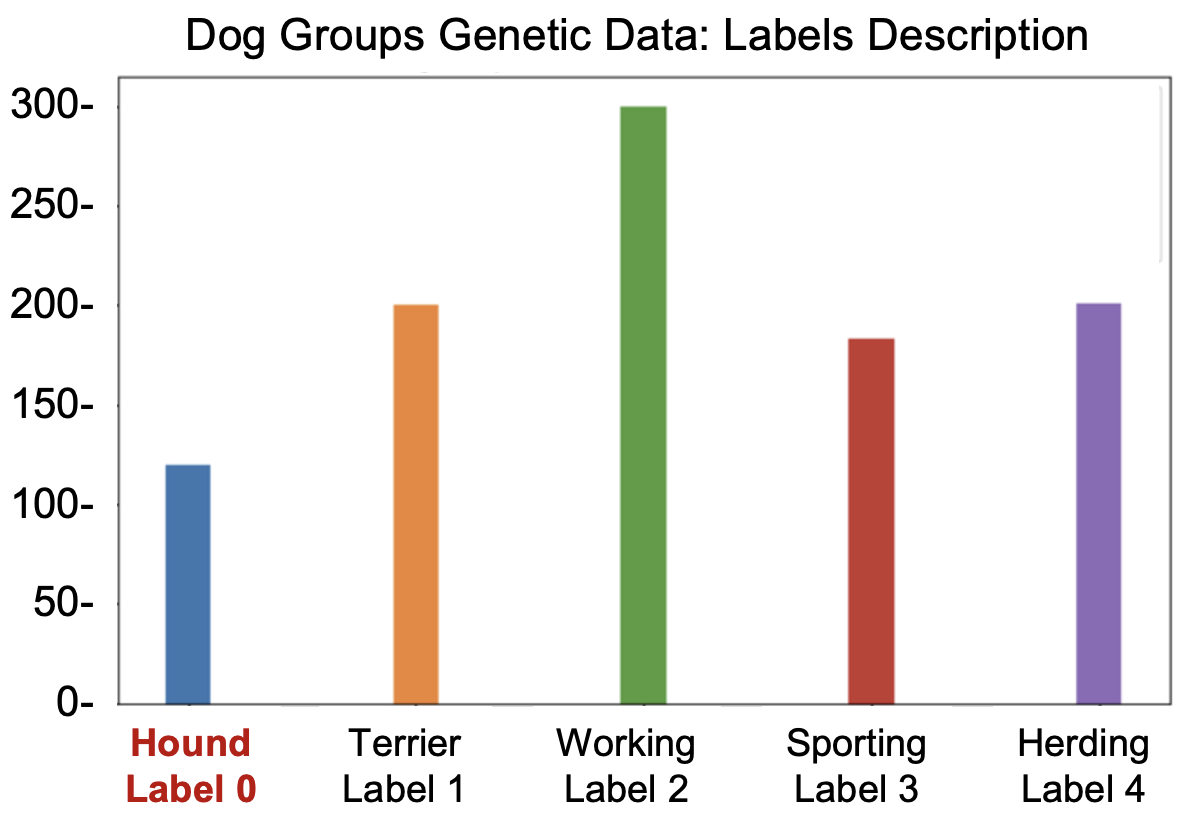
Look below for an example of gene variant data. Each column represents a gene, and the value of the column indicates whether a given plant’s gene varies from the “default” value. For instance the value “A/T” indicates that the default value of the gene is “A”, but instead this dog has value “T”. Some genes vary from default more than others, and different variants may have more or less importance for the dog's physical traits. Note that the records in the competitor's pack have been processed into a binary format ("one hot encoding") to make them easier for the models to work with; they're more machine readable and less human readable than the raw data below.
Executing a Membership Inference Attack:
Membership inference attacks in general operate by training an attack model to predict whether a record belongs to a given model’s training data. The idea is that the targeted model will have better confidence and accuracy on records it was trained on, as compared to records it hasn’t seen before. This is more likely to be true if the training data is very small or the model fit its data very closely.If we can prevent overfitting, that should reduce vulnerability to membership inference attacks. In the dog data problems we're going to explore two different ways to prevent overfitting. The first way is just by increasing the size of the record batch used during training. This means that more records are grouped together when the model is computing parameter updates, and that makes it less likely that the (for more background on client training and record batches, check out the Dog Problem 2 problem statement). The second way is by adding random noise during training to provide differential privacy noise. But we don't want to add more noise than we have to; the added noise significantly reduces the utility of the client models in the high privacy setting on the dog data. You’ll help us explore the effectiveness of these different protection methods in this problem.
We have four sets of client models for you to attack in the dog data problems (these same models are used in both problems):
- CNN Batch Size 5: These client models have no added noise, and have a small batch size possibly making them more likely to overfit the individual records in their training data.
- CNN Batch Size 40: These client models have no added noise, but they have a larger training batch size which may make it more difficult to attack individual records.
- Low Privacy DP: These client models have batch size 40 and also have noise added to every gradient computed during the training process, with privacy loss parameter set to 200. They perform nearly as well on the task as the regular CNN. Is their privacy protection any different than the regular CNN?
- High Privacy DP: These client models have batch size 40 and have added noise with privacy loss parameter epsilon set to 20. They should hopefully be private, but the added noise reduces their utility significantly on the dog data.
For each client model we will provide you with two sets of records to help train your attack:
- Relevant Records: These complete records (including correct dog breed label) are similar to the clients training data, but might or might not have been actually included in the client’s training data.
- External Records: These complete records (including correct dog breed label) are guaranteed to have not been included in the client’s training data.
How precisely do you train an attack model? Check out our resources page for libraries and references.
Dog Problem 1 Definition
You can find a link to the competitors pack with everything you need to prepare a submission on the Submit page.
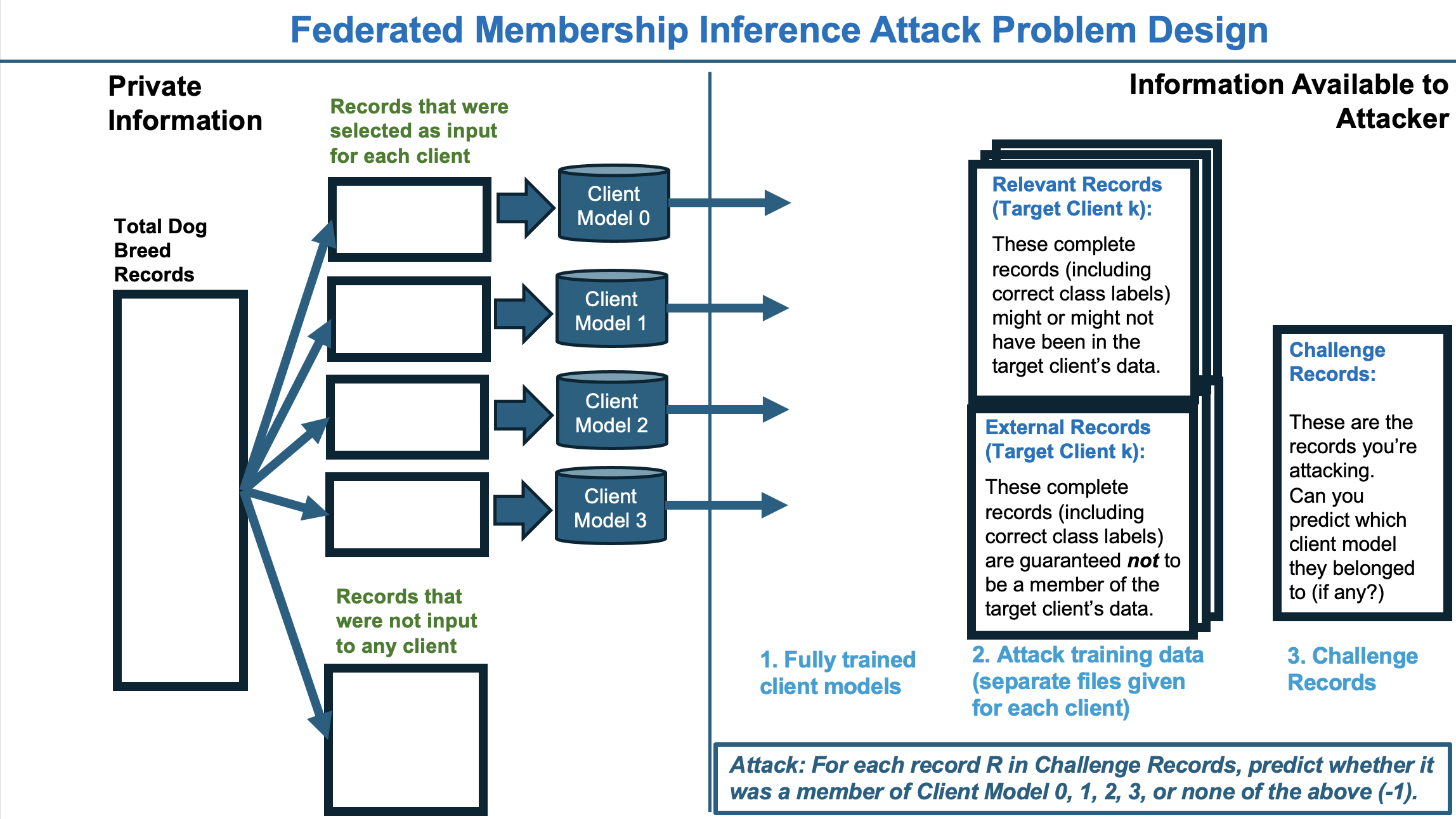
For each of our four privacy settings (CNN5, CNN40, DPLowPrivacy, DPHighPrivacy) we’ll provide the following (see Federated Membership
Inference Attack Design diagram above):
- Client models 0, 1, 2, 3. These represent the worst case for privacy, overtrained local models that the untrusted central aggregator might be able to attack. Like real world clients, they have different data distributions. Some may be easier to attack and some may be harder.
- Relevant records and External records for each client. This is data you can use to train your attack model, see Executing a Membership Attack for more information.
- Challenge Records. These are the records we want you to attack. Each record has a unique index number. For each record, predict whether it belongs to client 0, 1, 2, 3 or write -1 if none of the above.
Dog Problem 1 Submission Format
For each of the four privacy settings, submit a Challenge Record Prediction csv file with the challenge record index number and your prediction for which client it belongs to: 0, 1, 2, 3 or -1 for none.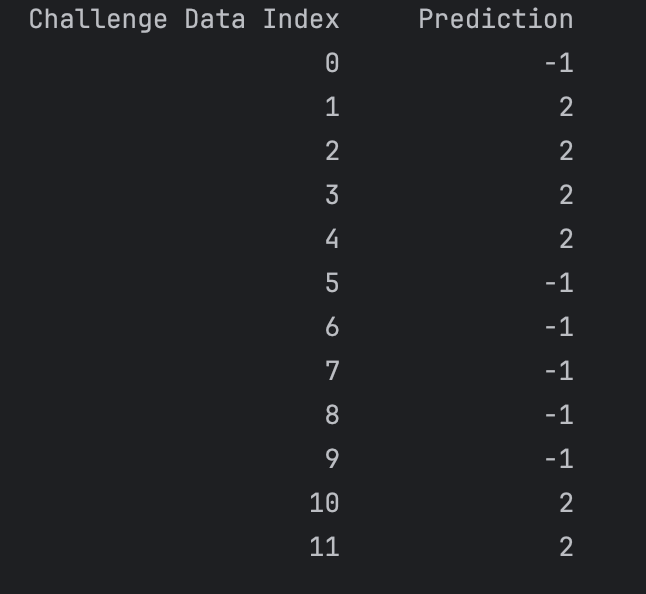
We’ll also ask you for any references (papers, libraries, etc) relevant to your submission, a short description of your approach, an estimate of the computation time/power needed for your approach, and whether you’d like to be included in our Techniques showcase.
Dog Problem 1 Submission Schedule:
Check the Calendar for the leaderboard deadline. Submit your predictions for the challenge records by the deadline, and you’ll get back a percentage accuracy on the Leaderboard.You can submit up to three attack attempts, using different approaches/configurations. Your team will be scored by your highest performing entry. This gives you a chance to try out multiple libraries or ideas. We’ll be rating different attack libraries by how successful they are, and sharing what we learn about the overall privacy protection of different client models. The goal here isn’t just to get at the top of the leaderboard, it’s to find out together in a realistic setting how attacks behave, and how safe these models really are.
Dog Problem 1 Practice data:
In each problem we'll provide you with some demonstration data; essentially a part of the problem where we give you the answers for free, so you can try out different techniques locally before you submit. For the dog data problem 1, the competitor's pack includes the membership list for Client 2.Problem 2: Reconstruction Attack
Recall that in federated learning, the clients exchange model training information with the central model. Clients first compute model gradients based just on their local data. They send these to the Central Model which averages them together. Each round the clients get a new average gradient from the central model and then compute a series of updates to it based on samples (batches) from their local data.For this problem we look into whether an attacker can use leaked local client gradients to reconstruct genetic records, and whether an attacker can reconstruc records well enough to learn a specific piece of sensitive information about them. On human data an attacker might try to infer the presence of a medical condition or sensitive genetic trait in the training data. For our dog data, we're going to have you hunt for hounds.
Research Questions: For problem 2 on the dog breed data, we tackle a worst case senario for reconstruction: What happens when the federated system leaks gradient upates during local training? We want to explore the following important questions:
- Are the regular CNN’s vulnerable to membership inference attacks?
- Do larger batch sizes reduce models' vulnerability to attacks, as compared to small batch sizes?
- Can differential privacy help protect client data?
- Different clients have different local data distributions– does the effectiveness of differential privacy differ for different clients?
Machine Learning Data and Task: The task the models are trained to do here is predict dog breed group based on genetic data. The columns in the data have been reduced to gene variants relevant for this task.The overall distribution of dog breed group labels in the population as a whole looks like this:
The overall distribution of dog breed group labels in the population as a whole looks like this:
Executing a Reconstruction Attack:
The competitors pack provides data and models needed to attack local training across four clients. We assume that the federated system leaks six gradients from each client. The diagram below illustrates the two tasks in this problem: Reconstruct Three and Hound Hunt.
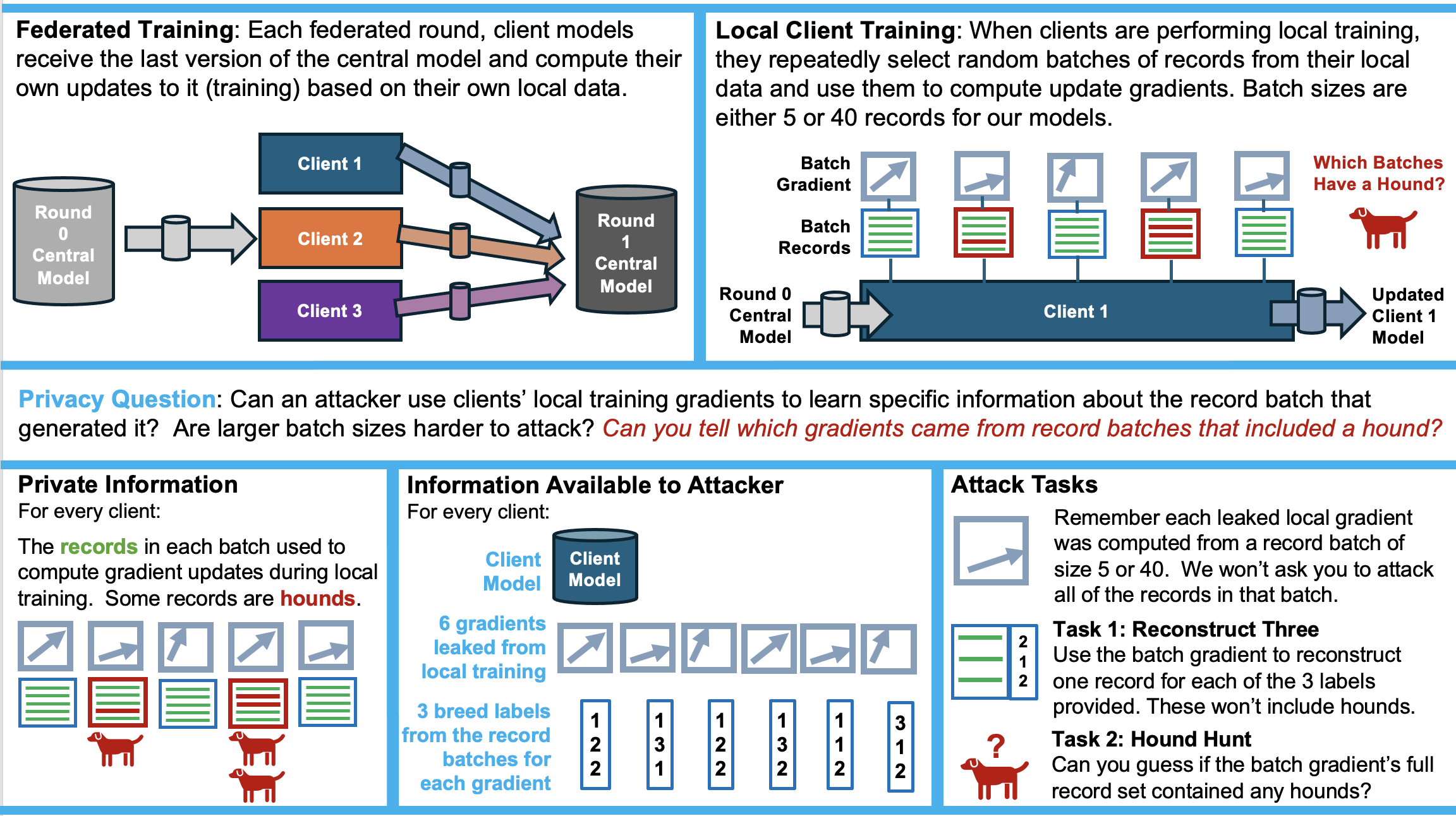
The Hound Hunt task is an opportunity for creativity; there are many different ways you might try to determine whether a given gradient's record batch included one or more hound records. The Breaching library will reconstruct full record batches with and without labels, and you should remember that the client models have been trained to predict whether records are hounds. The notebook provides one example hound hunt attack approach, but we hope you'll explore other possibilities as well.
We have four sets of client models for you to attack, at different privacy levels:
- CNN Batch Size 5: These client models have no added noise, and have a small batch size possibly making them more likely to overfit the individual records in their training data.
- CNN Batch Size 40: These client models have no added noise, but they have a larger training batch size which may make it more difficult to attack individual records.
- Low Privacy DP: These client models have batch size 40 and also have noise added to every gradient computed during the training process, with privacy loss parameter set to 200. They perform nearly as well on the task as the regular CNN. Is their privacy protection any different than the regular CNN?
- High Privacy DP: These client models have batch size 40 and have added noise with privacy loss parameter epsilon set to 20. They should hopefully be private, but the added noise reduces their utility significantly on the dog data.
Dog Data Problem 2 Red Team Challenge
You can find a link to the competitors pack with everything you need to prepare a submission on the Submit page.
For each of our four privacy settings (CNN5, CNN40, DPLowPrivacy, DPHighPrivacy) we’ll provide the following:
- Client models 0, 1, 2, 3 These are the exact same models used in Dog Data Problem 1.
- Challenge gradients and record labels, for each client we provide six gradients, and for each gradient we provide the full batch size and three record labels to attack (these labels never include hounds). This is the leaked information you use for your attack, see Executing a Reconstruction Attack for more information.
Dog Data Problem 2 Submission Format and Scoring:
For each of the four privacy settings, we provide submission csv files to make it easy to submit the results of your reconstruction attack and hound hunt. There's a separate submission file for Task 1 (Reconstruct Three) and Task 2 (Hound Hunt). The tutorial notebook in the competitor's pack provides a walkthrough for creating a submission.Task 1 "Reconstruct Three": The reconstruction attack submission file is formatted as shown below: the first column gives the client number, the second column gives the gradient number (there are six gradients for each client), and the third column gives the label of the record you're reconstructing. The remaining columns will be all 0's (placeholder values) and should be replaced with the reconstructed record values.
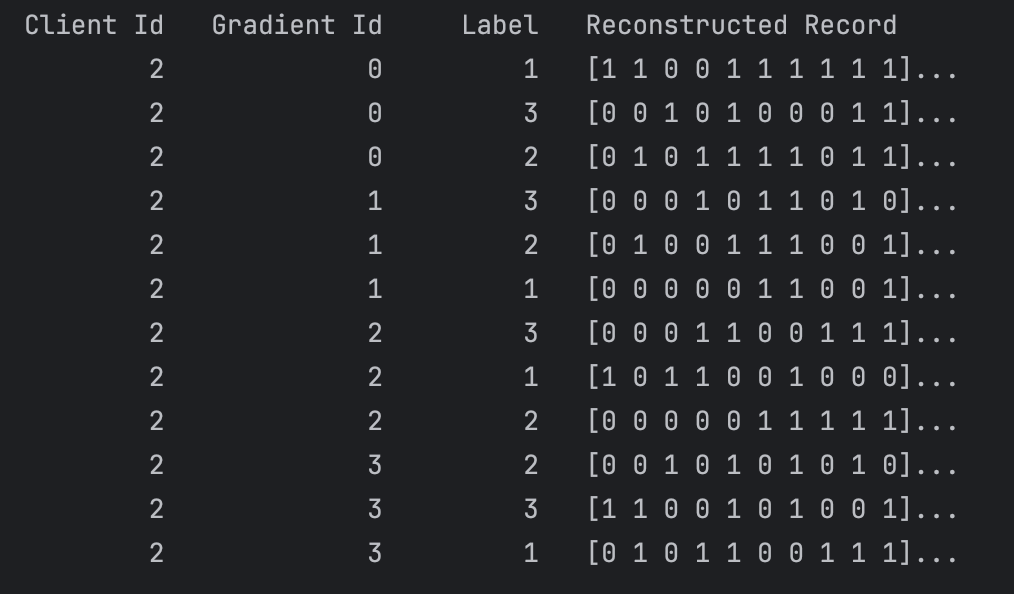
Note that we're only asking you to reconstruct 3 records from training batches that actually contain approximately 5 or 40 samples (batch sizes vary slightly on DP models). When we score your submission, we'll first match each of your three reconstructed records with the most similar real record in the training batch, and then we score how closely they reconstructed their matched record. Scoring is based on counting how many genes match between the original record and the reconstructed record, with a focus on genes of interest (selected genes with high entropy). Although the data is provided in binary format (known as one-hot encoding), the competitor's pack notebook also includes a scoring function that reverts the data to gene variant format for computing gene similarity scores.
Task 2 "Hound Hunt": The hound hunt attack submission file is shown below: The first two columns are the same as in Task 1, the client number and gradient number (with six gradients per client). The third column then asks if that gradient's record batch contained any hounds, and the fourth column asks if had several hounds (more than 4 for the models with batch size 40). These last two columns will be all 0's (placeholder values) and should be replaced with your hound hunt answers (1 if true, 0 if false).
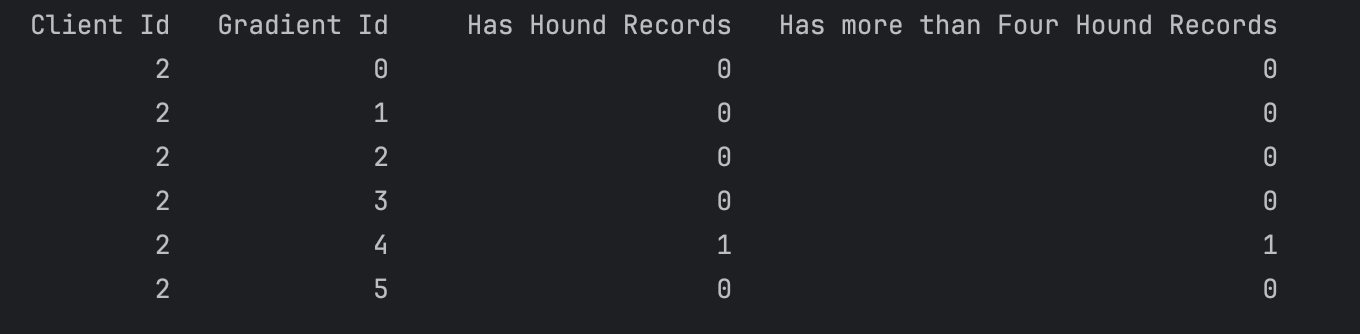
We’ll also ask you for any references (papers, libraries, etc) relevant to your submission, a short description of your approach, an estimate of the computation time/power needed for your approach, and whether you’d like to be included in our Techniques showcase.
Dog Data Problem 2 Submission Schedule:
Check the Calendar for the leaderboard deadline. Submit your predictions for the challenge records by the deadline, and you’ll get back a percentage accuracy on the Leaderboard.You can submit up to three attack attempts, using different approaches/configurations. Your team will be scored by your highest performing entry. This gives you a chance to try out multiple libraries or ideas. We’ll be rating different attack libraries by how successful they are, and sharing what we learn about the overall privacy protection of different client models. The goal here isn’t just to get at the top of the leaderboard, it’s to find out together in a realistic setting how attacks behave, and how safe these models really are.