Report created on: March 15, 2023 21:44:40
Created with SDNIST v2.1.0
Data Description
Deidentified (Deid.) Data:
| Label Name | Label Value |
|---|---|
| Team | CCAIM |
| Submission Timestamp | 3/9/2023 3:17:40 |
| Algorithm Name | Synthcity-DPGAN |
| Variant Label | synthcity-dpgan-default |
| Property | Value |
|---|---|
| Filename | dpgan-ZhaozhiQian |
| Records | 21802 |
| Features | 24 |
Target Data:
| Property | Value |
|---|---|
| Filename | national2019 |
| Records | 27253 |
| Features | 24 |
Evaluated Data Features:
| Feature Name | Feature Description | Feature Type | Feature Has 'N' (N/A) values? |
|---|---|---|---|
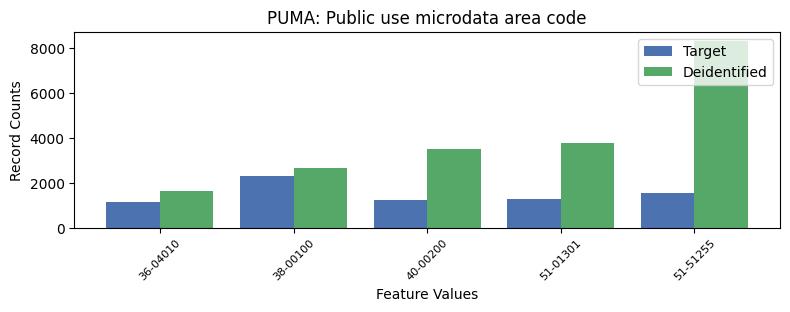
| PUMA | Public use microdata area code | object of type string | False |
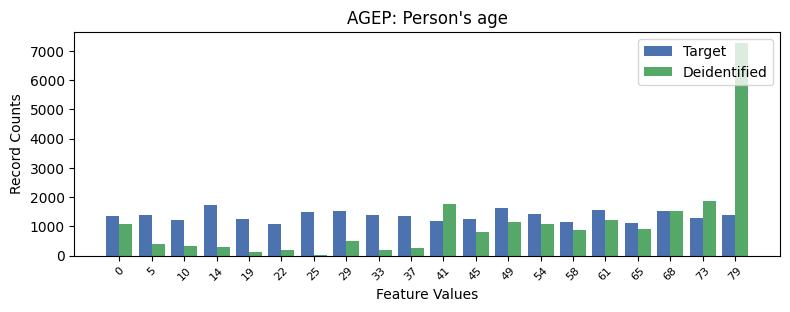
| AGEP | Person's age | int64 | False |
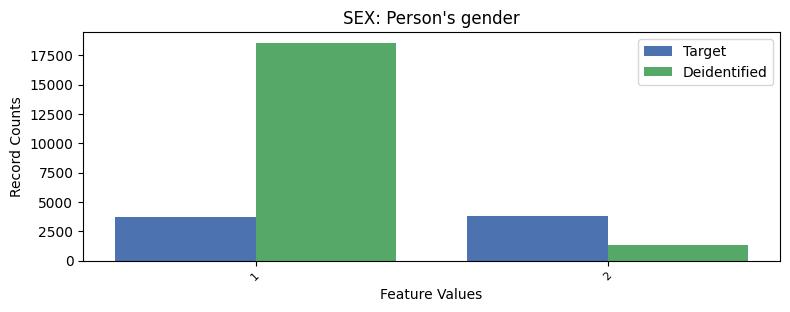
| SEX | Person's gender | int64 | False |
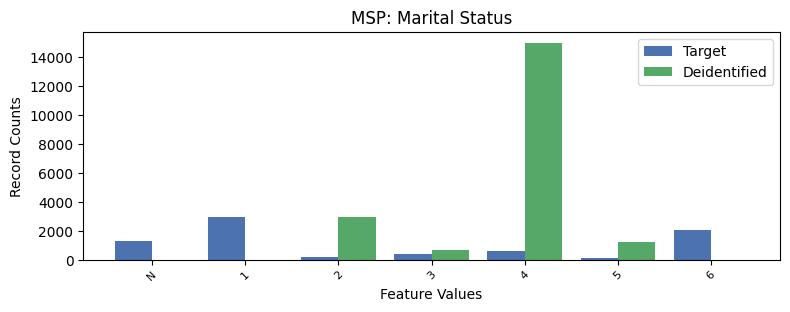
| MSP | Marital Status | object of type string | True |
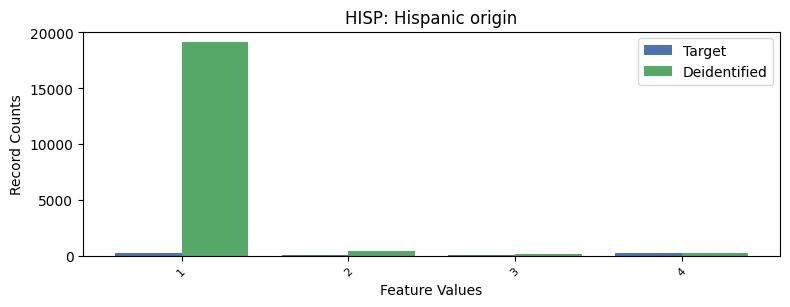
| HISP | Hispanic origin | int64 | False |
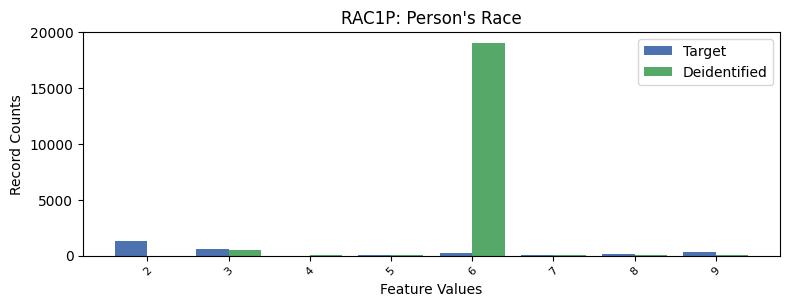
| RAC1P | Person's Race | int64 | False |
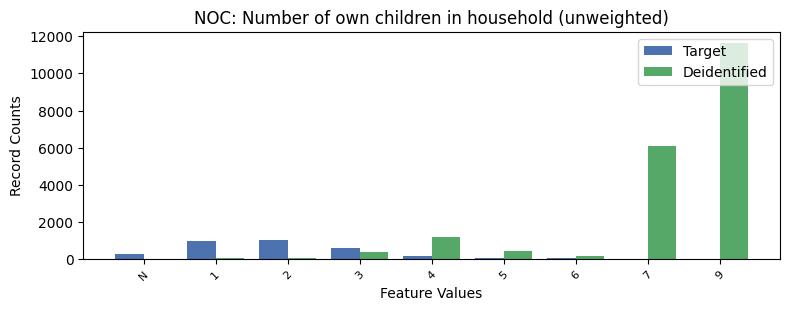
| NOC | Number of own children in household (unweighted) | object of type string | True |
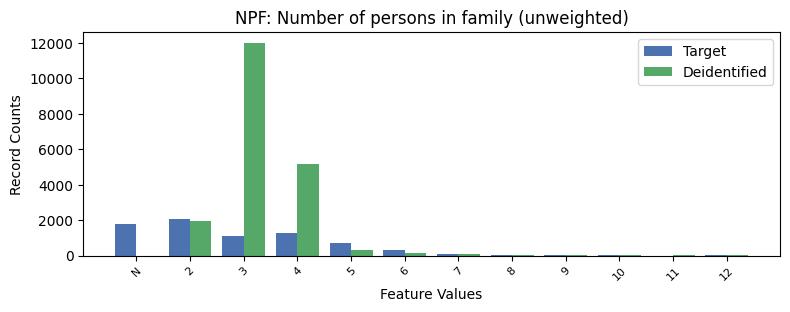
| NPF | Number of persons in family (unweighted) | object of type string | True |
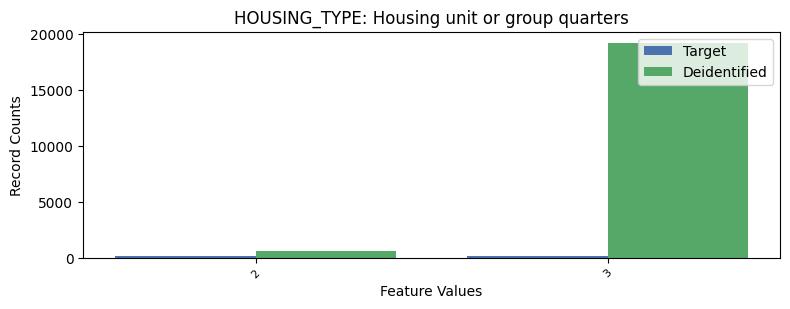
| HOUSING_TYPE | Housing unit or group quarters | int64 | False |
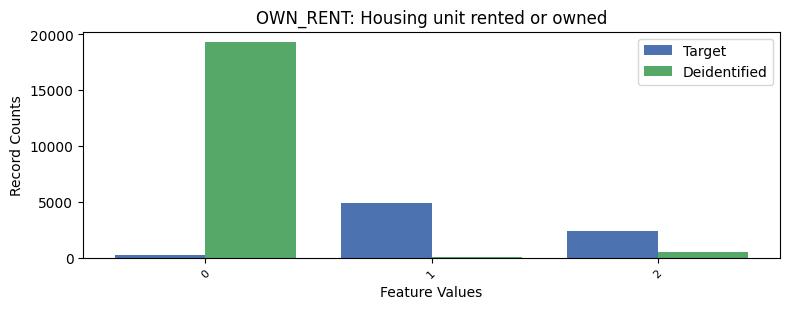
| OWN_RENT | Housing unit rented or owned | int64 | False |
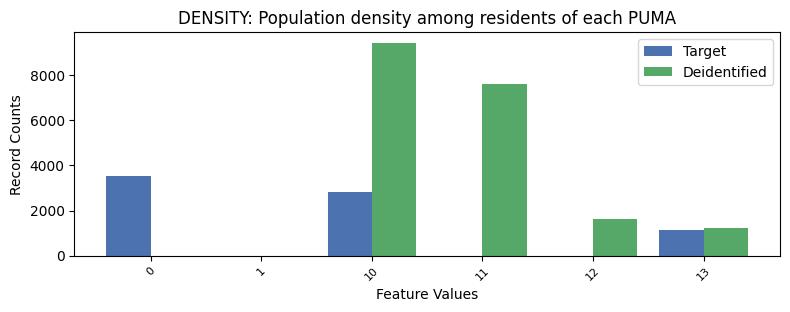
| DENSITY | Population density among residents of each PUMA | float64 | False |
| INDP | Industry codes | object of type string | True |
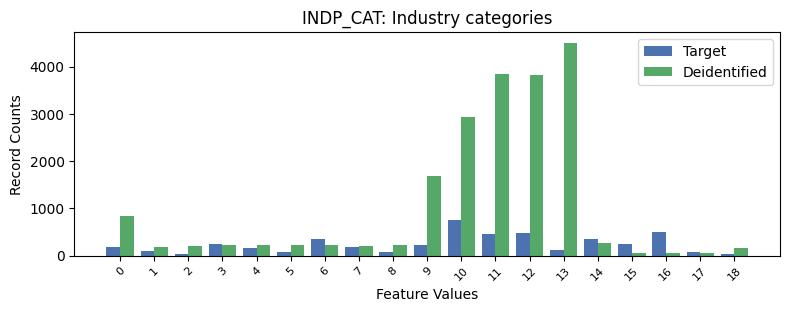
| INDP_CAT | Industry categories | object of type string | True |
| EDU | Educational attainment | object of type string | True |
| PINCP | Person's total income in dollars | object of type string | True |
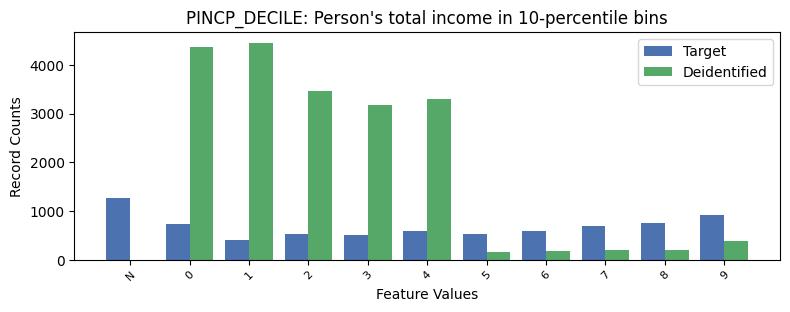
| PINCP_DECILE | Person's total income in 10-percentile bins | object of type string | True |
| POVPIP | Income-to-poverty ratio (ex: 250 = 2.5 x poverty line) | object of type string | True |
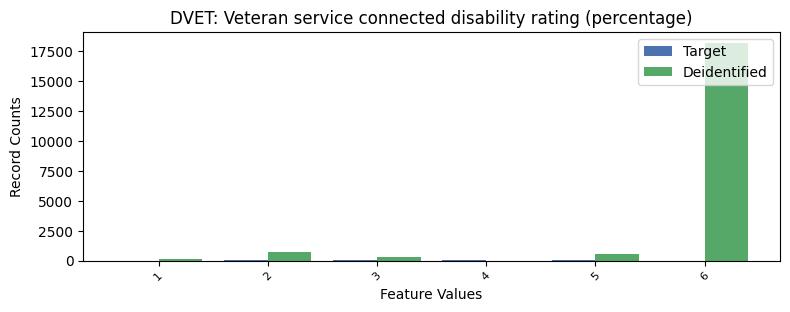
| DVET | Veteran service connected disability rating (percentage) | object of type string | True |
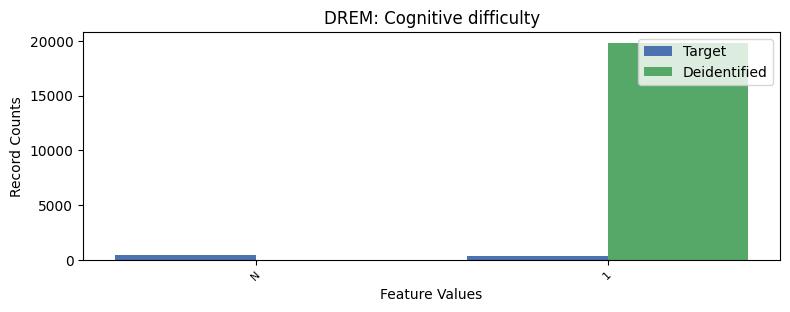
| DREM | Cognitive difficulty | object of type string | True |
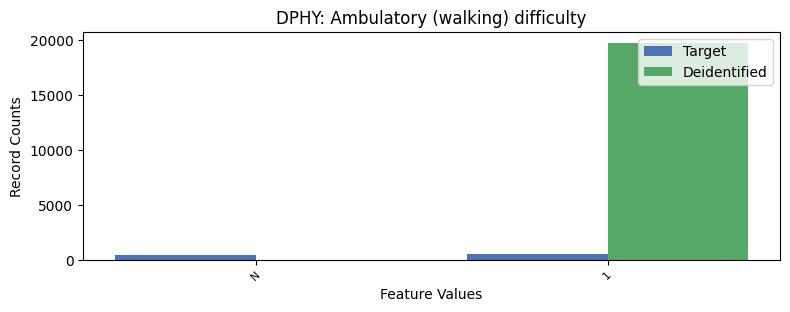
| DPHY | Ambulatory (walking) difficulty | object of type string | True |
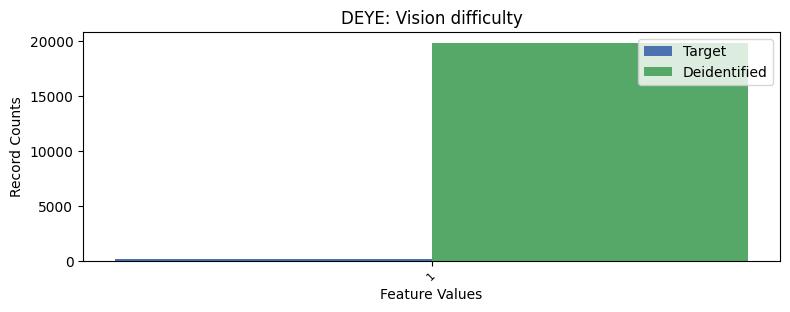
| DEYE | Vision difficulty | int32 | False |
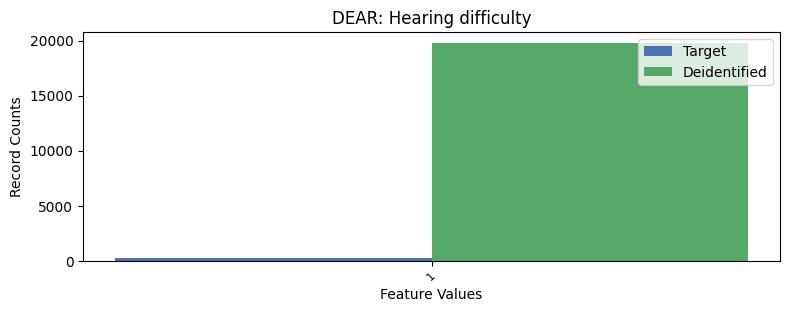
| DEAR | Hearing difficulty | int32 | False |
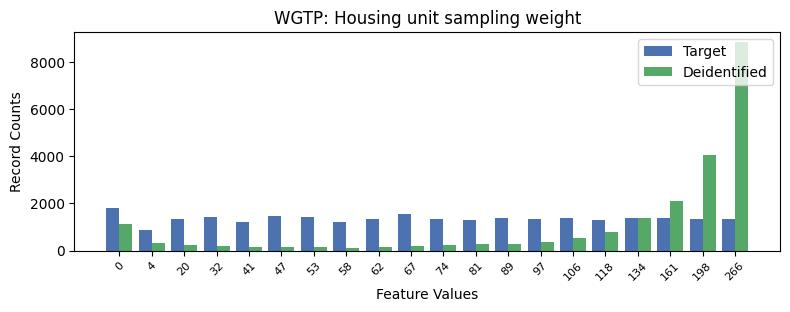
| WGTP | Housing unit sampling weight | int64 | False |
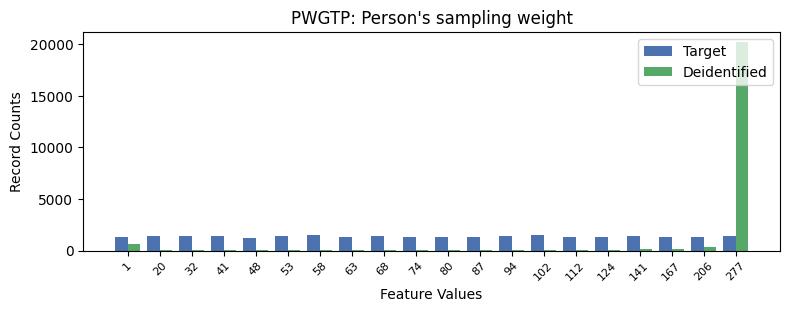
| PWGTP | Person's sampling weight | int64 | False |
Utility Evaluation
K-Marginal Synopsys:
Univariate Distributions:
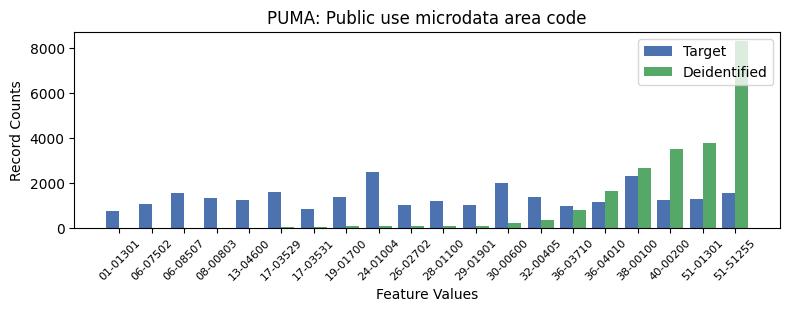
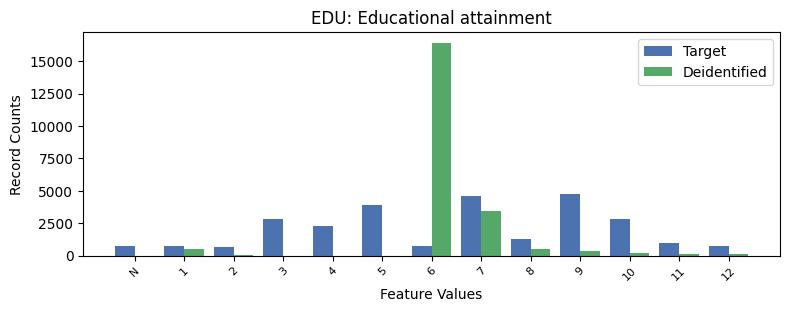
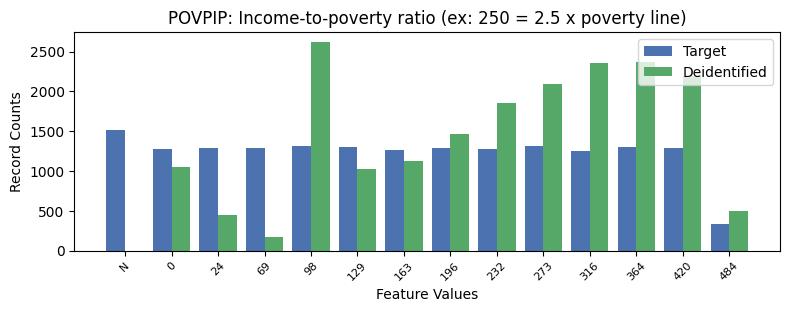
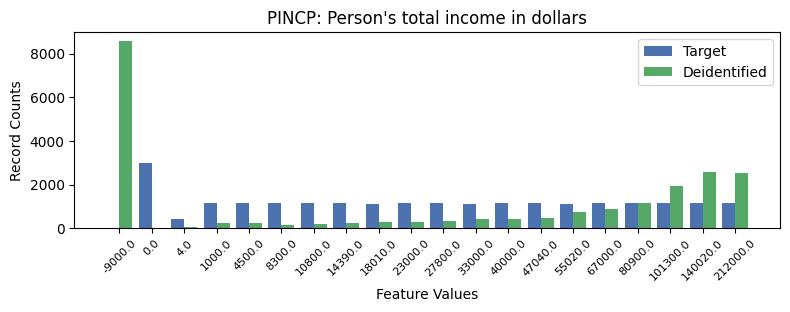
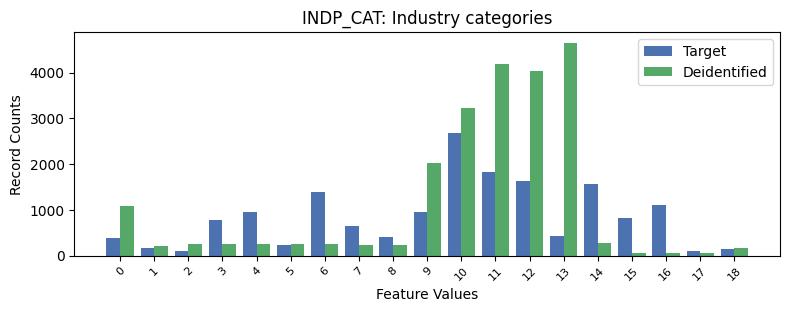
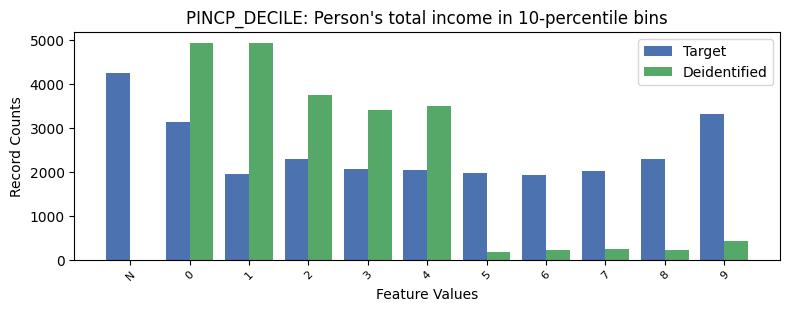
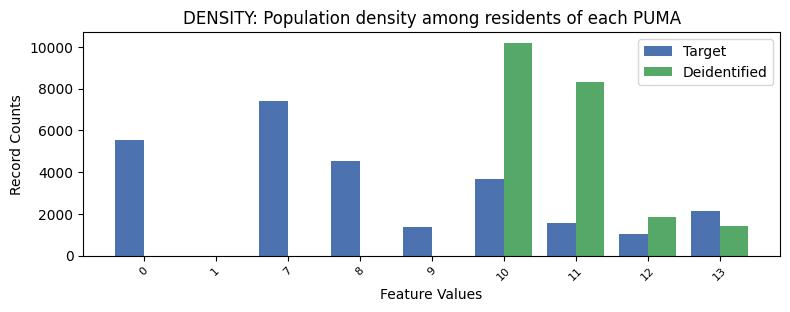
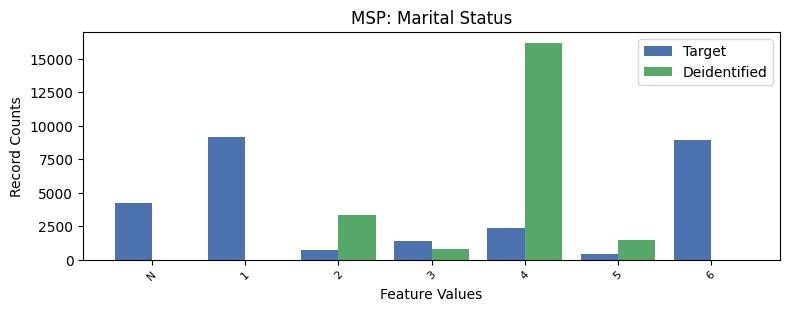
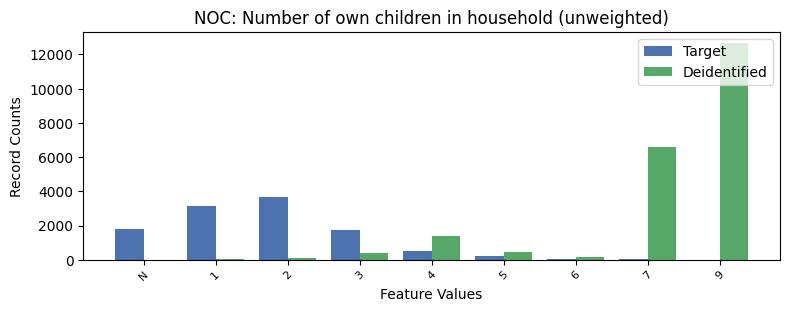
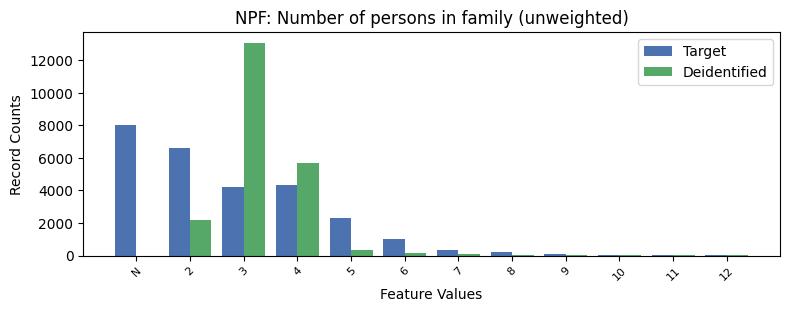
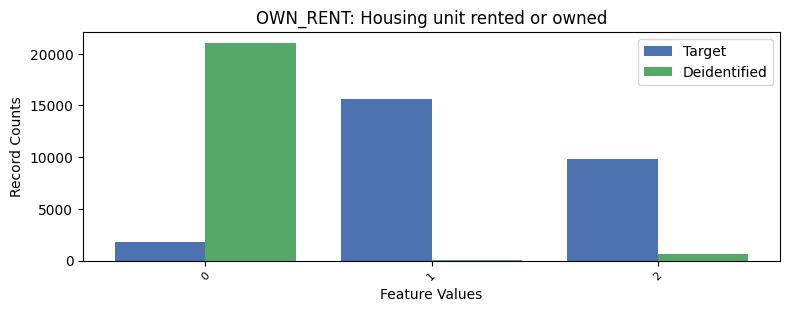
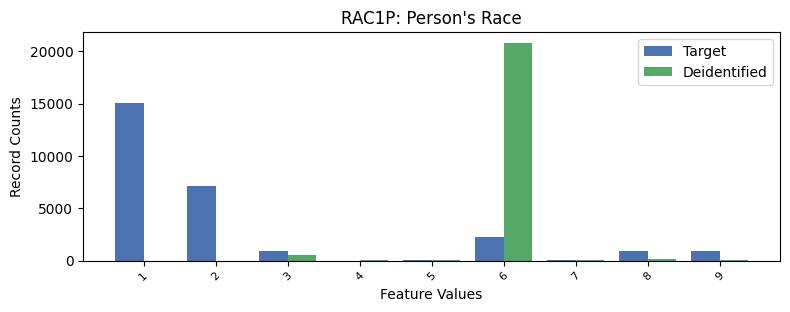
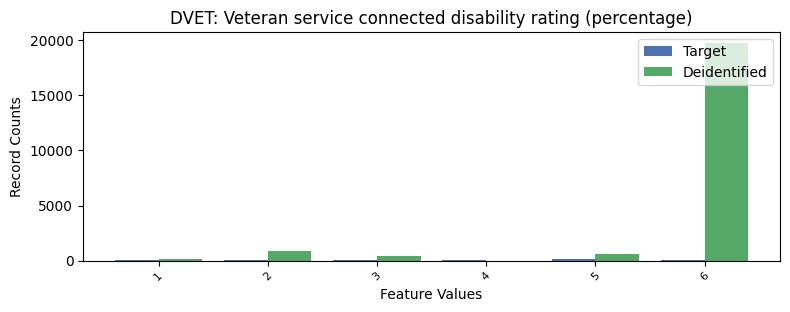
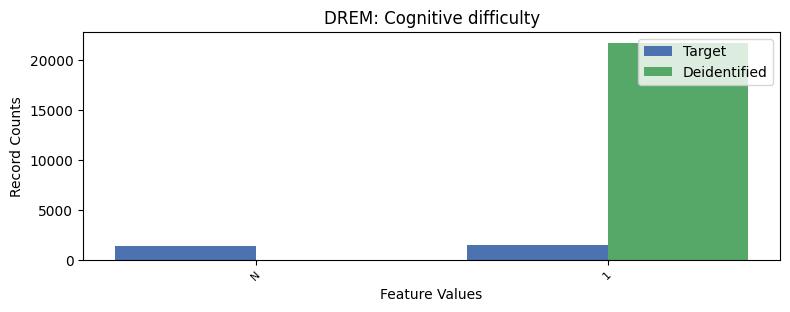
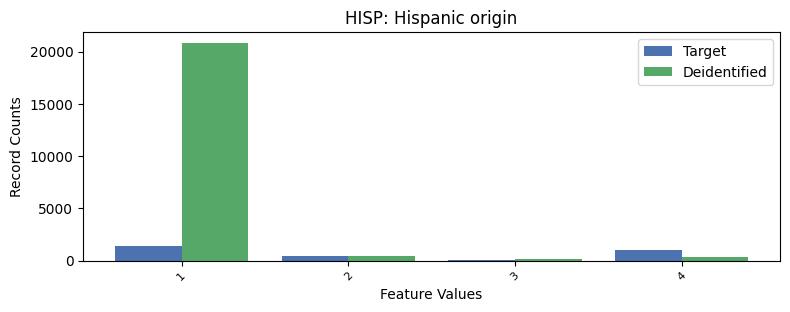
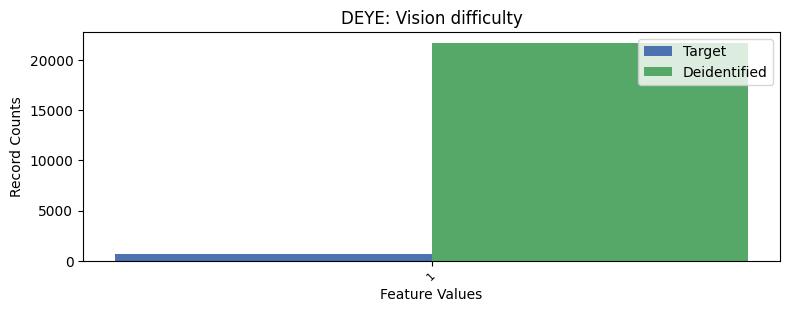
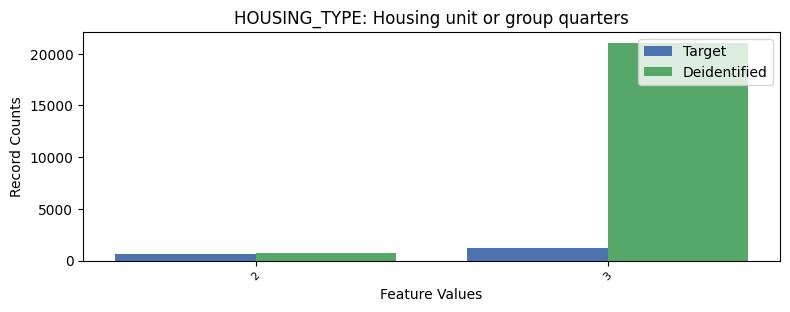
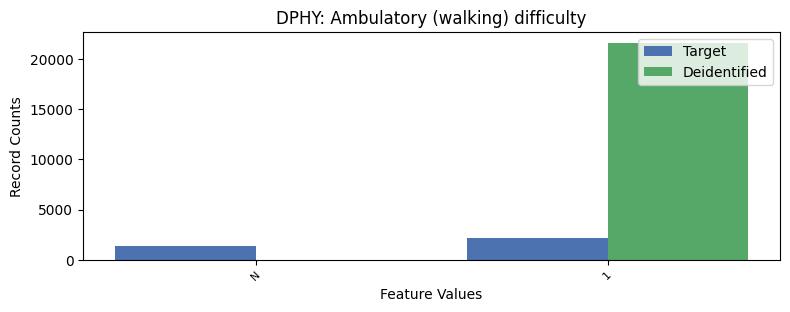
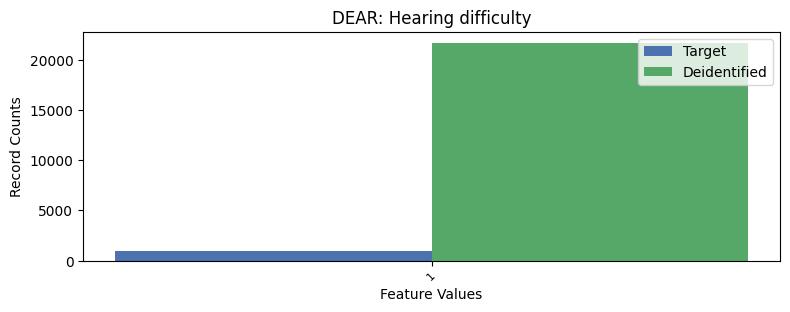
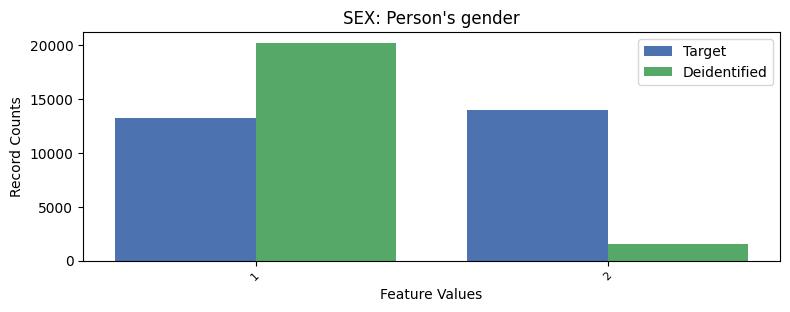
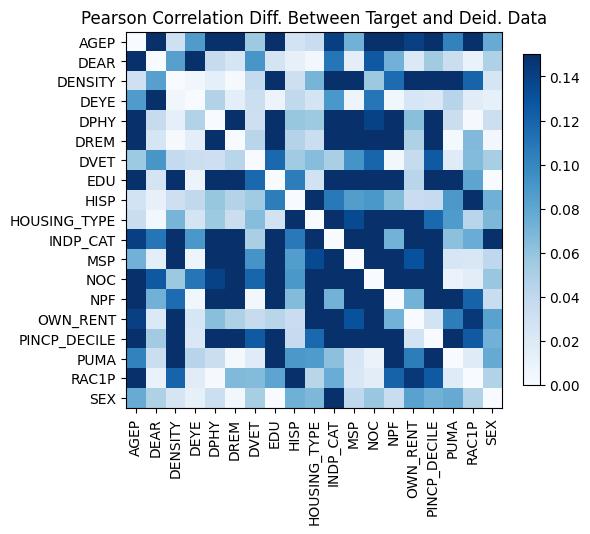
Correlations:
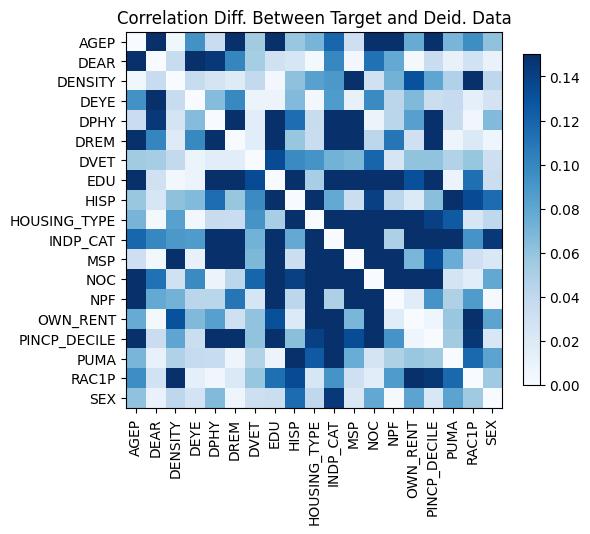
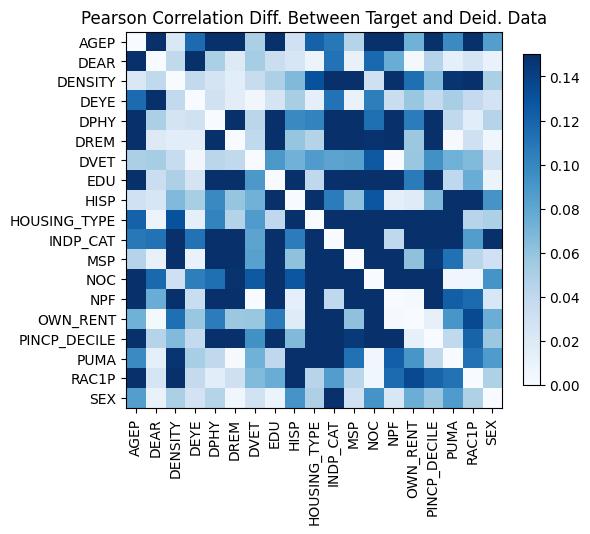
Linear Regression:
Total Population:
Target Data:
23006 records, 100.0% of adult (>15) data
Regression: 0.63 slope, -0.1 intercept
Deidentified Data:
21802 records, 100.0% of adult (>15) data
Regression: -0.05 slope, 2.45 intercept

White Men:
Target Data:
6463 records, 28.09% of adult (>15) data
Regression: 0.68 slope, 0.39 intercept
Deidentified Data:
1 records, 0.0% of adult (>15) data
Regression: 0 slope, 0 intercept

White Women:
Target Data:
6505 records, 28.28% of adult (>15) data
Regression: 0.66 slope, -0.6 intercept
Deidentified Data:
1 records, 0.0% of adult (>15) data
Regression: 0 slope, 0 intercept

Black Men:
Target Data:
2720 records, 11.82% of adult (>15) data
Regression: 0.52 slope, 0.45 intercept
Deidentified Data:
0 records, 0.0% of adult (>15) data
Regression: 0 slope, 0 intercept

Black Women:
Target Data:
3366 records, 14.63% of adult (>15) data
Regression: 0.51 slope, 0.3 intercept
Deidentified Data:
0 records, 0.0% of adult (>15) data
Regression: 0 slope, 0 intercept

Asian Men:
Target Data:
914 records, 3.97% of adult (>15) data
Regression: 0.7 slope, -0.68 intercept
Deidentified Data:
19388 records, 88.93% of adult (>15) data
Regression: -0.08 slope, 2.6 intercept

Asian Women:
Target Data:
982 records, 4.27% of adult (>15) data
Regression: 0.55 slope, -0.19 intercept
Deidentified Data:
1408 records, 6.46% of adult (>15) data
Regression: 0.07 slope, 1.5 intercept

American Indian, Alaskan Native and Native Hawaiians (AIANNH) Men:
Target Data:
376 records, 1.63% of adult (>15) data
Regression: 0.42 slope, 1.18 intercept
Deidentified Data:
665 records, 3.05% of adult (>15) data
Regression: -0.03 slope, 2.3 intercept

American Indian, Alaskan Native and Native Hawaiians (AIANNH) Women:
Target Data:
395 records, 1.72% of adult (>15) data
Regression: 0.54 slope, -0.19 intercept
Deidentified Data:
140 records, 0.64% of adult (>15) data
Regression: -0.08 slope, 2.57 intercept

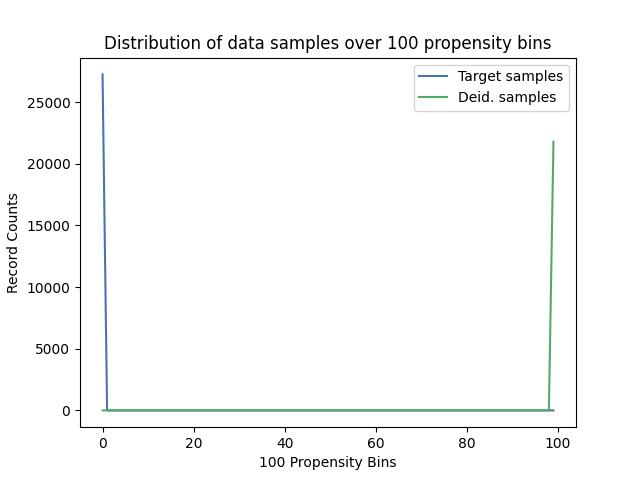
Propensity Mean Square Error:
Propensities Distribution:
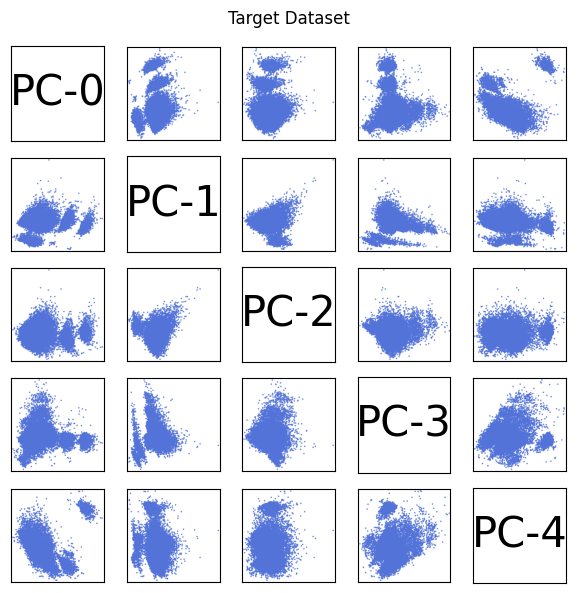
PCA:

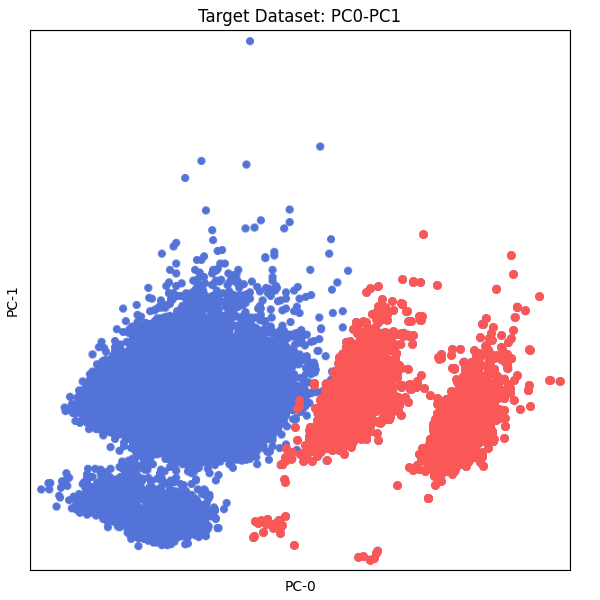
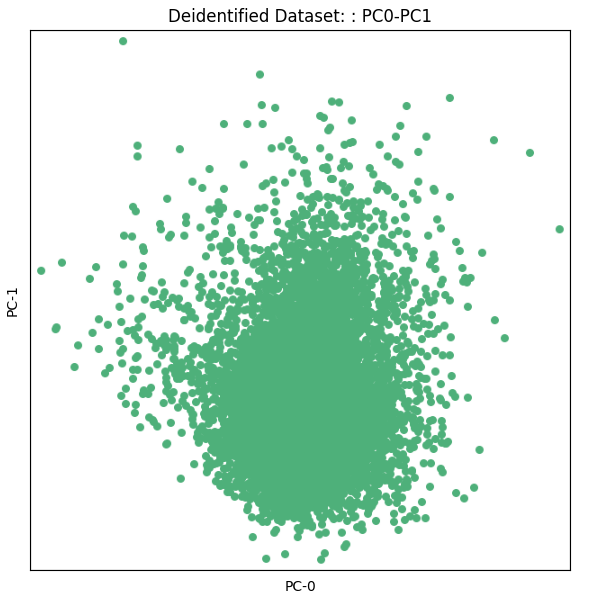
Inconsistencies:
K-Marginal Score Breakdown:
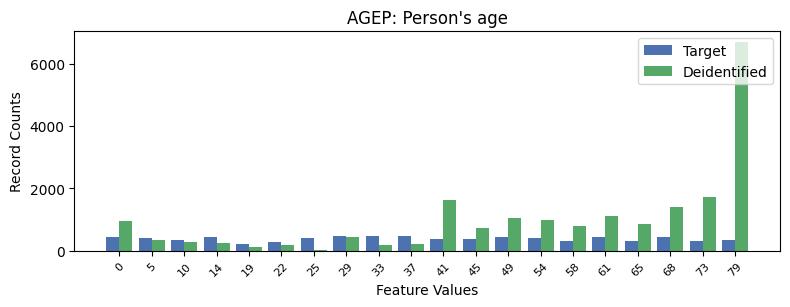
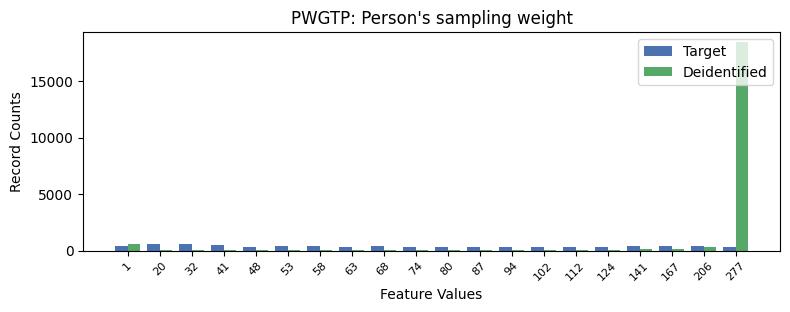
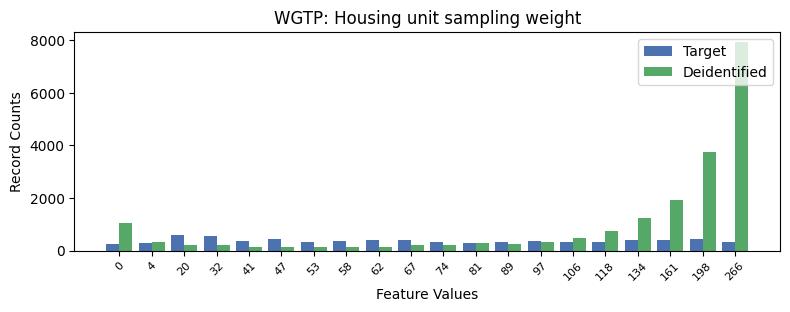
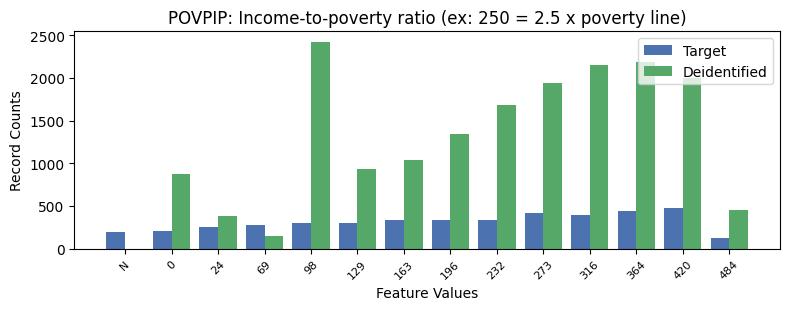
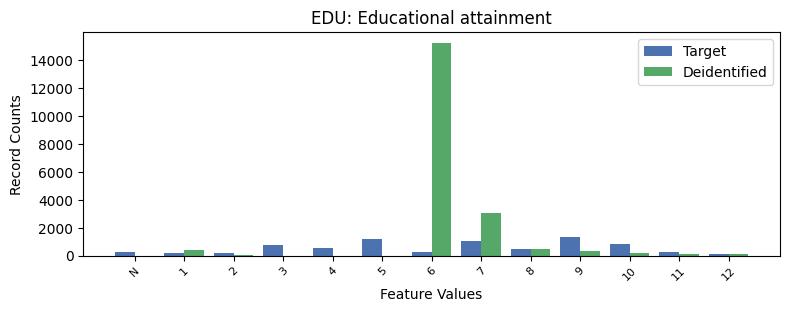
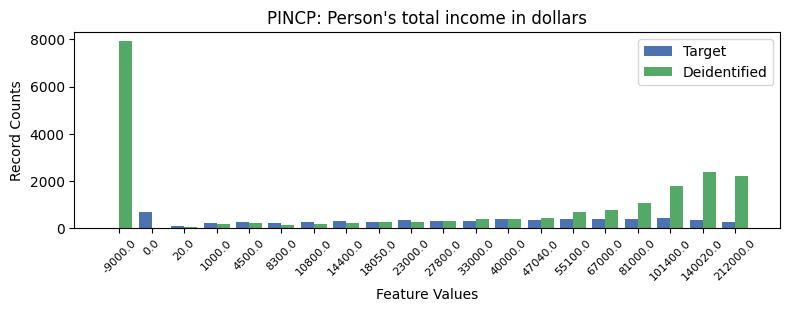
Privacy Evaluation
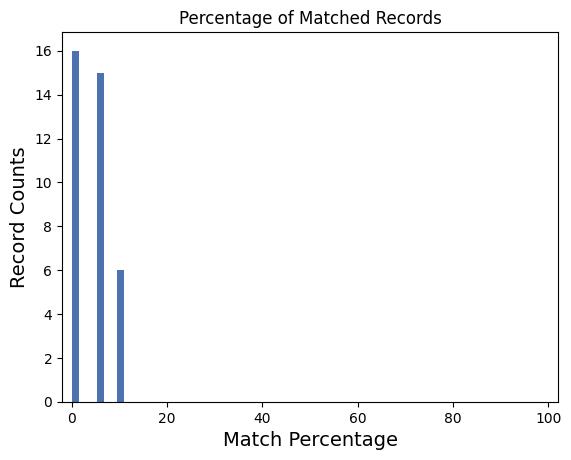
Apparent Match Distribution: